PEGASUS 项目(即高度自动驾驶功能发布的一般公认质量标准、工具和方法以及场景和情况的建立项目)由德国联邦经济事务和能源部 (BMWi) 资助。它旨在研究用于验证和验证高度自动驾驶功能 (SAE L3 级以上) 的新方法。示例测试对象是用于高速公路的高级别 L3 自动驾驶功能(高速公路自动驾驶)。
PEGASUS 项目中的测试对象自动驾驶功能是在系统层面进行描述的。在整个项目中,测试对象被视为一个黑盒子。项目重点不在于详细查看整车架构或其他单个组件及其架构,也没有明确处理或测试它们。这需要通过额外的系统测试来定义。除了其他用于自动驾驶验证和验证所需的其他项目之外,PEGASUS 还提供论证和相应的证据。评估方法提供了一种通过测试提高安全性的概念,与目前方法中未包含的安全设计概念或类似概念形成对比。这在进一步的研究项目中可能会被考虑,但需要进行审查。
为了定义用于验证和验证自动驾驶功能的新技术水平,该项目内的四个子项目对不同的测试方法、质量标准、交通场景、工具和指南进行了分析。四个子项目的成果相互高度依赖。因此,不同子项目的多个研究成果通过迭代过程结合起来,定义了评估高度自动驾驶功能的通用 PEGASUS 方法,如图 2 所示。该处理链和方法不同元素之间接口的概述提供了每个详细思考的起点。
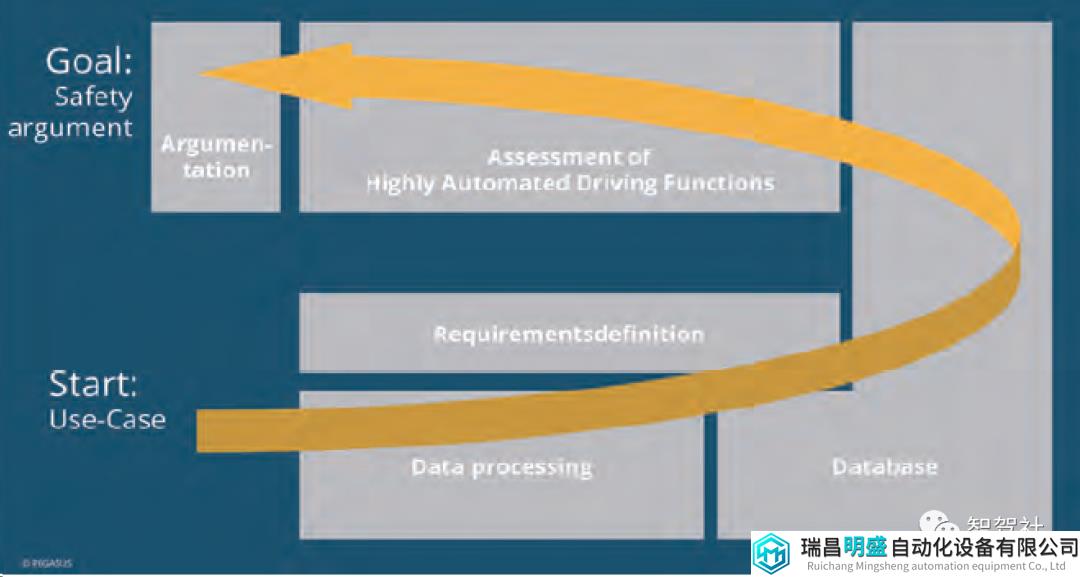
本文概述了 PEGASUS 方法的架构。重点放在方法的 21 个不同元素的主要目标以及这些元素之间的联系。
PEGASUS 方法的右侧描述了创建验证和验证证据的过程,其中包括所有步骤和中间接口 (1) – (20)。在左侧,位于安全论证 (21)。该论证 (左侧) 将与 PEGASUS 方法结束时证据过程的结果 (右侧) 进行比较,以便为与驾驶功能或测试对象相关的安全声明做出贡献。这可以用于整体发布推荐。
整个方法的流程图从左下角逆时针读取到左上角,包括验证和验证高度自动驾驶功能的五个基本元素:
需求定义数据处理数据库中的信息存储和处理高度自动驾驶功能评估论证
在这些基本元素中,所有用于验证和验证高度自动驾驶功能的相关方法都按五个顺序执行的流程步骤进行分组。使用 PEGASUS 方法的每一次都会逐个使用这些流程步骤。
第一个元素是数据处理。输入信息尤其包括给定的用例(测试对象的项目定义)和先前执行的 PEGASUS 方法循环的现有结果。此流程步骤的第一个目标是基于抽象知识系统地识别与测试对象相关的逻辑场景。这些直接转移到数据库中。第二个目标是将现有记录的场景转换为通用格式。此步骤为了在数据库中使用不同类型的信息源是必要的。数据处理的方法将在后面详细描述。此处理步骤的输出是逻辑场景和以前执行的场景的信息,采用通用格式。
第二个元素——需求定义,将与之前描述的元素并行执行。输入仍然是给定的用例、项目定义或先前循环的 PEGASUS 方法的结果。在第二个元素中,抽象知识用于定义自动驾驶功能的需求或测试对象的通用行为需求。这些需求将用于数据库中,将评估标准添加到场景中,并将它们组合成测试用例。此外,已识别的需求还用于定义第四个元素——高度自动驾驶功能评估的流程规范。
第三个元素是数据库。在这个元素中,来自第一个元素的通用格式的准备数据集被用于将信息分配给预定义的逻辑场景。此外,准备好的数据集用于定义不同场景参数的参数空间。利用这些信息,数据库创建一个逻辑测试用例空间,其中包含来自第二个元素的不同逻辑场景的集成通过和失败标准。
第四个元素是高度自动驾驶功能评估,在仿真器中执行并随后在试验台上验证逻辑场景。系统的现场测试也将提供额外的发现。测试执行的结果与通过和失败标准进行比较以进行评估。它们用于风险评估以定义安全声明。
在最后一个元素中,生成的证据与预定义的安全论证进行比较。比较是在外部程序模型中执行的。
方法元素的详细描述
先前命名的基本元素由不同类型的内容(数据)组成,如图 3 所示为数据容器,如图 3 所示为菱形的过程步骤(程序)。PEGASUS 方法中,数据容器包含由各种过程步骤创建的不同类型信息。在每种情况下,它们都包含来自先前过程步骤的结果,因此是下一个步骤的主要基础。这些容器包括例如测量数据、场景、测试数据等。在过程步骤中,使用不同的方法根据输入创建新的输出信息,例如事故信息的重建。
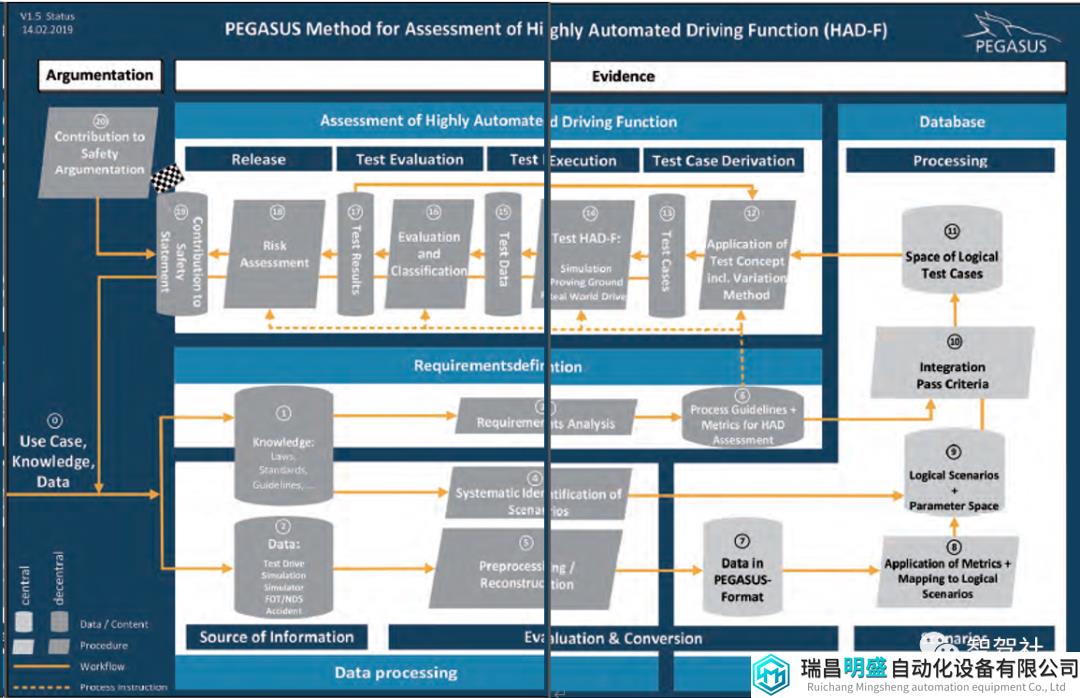
PEGASUS 方法的每次使用都会逐个使用这些过程步骤。以下,简要描述方法的所有步骤。
数据处理 (1,2,4,5)
PEGASUS 方法从数据处理过程步骤开始,使用给定的用例以及所有与用例或测试对象相关的现有日志数据和抽象知识。数据处理过程步骤以两种方式执行。一方面,抽象知识 (1) 用于系统识别场景 (4) 以定义逻辑场景 (9)。另一方面,测量数据 (2) 在预处理/重建 (5) 过程步骤中进行准备,以便为数据库创建通用格式 (7) 的数据。
在大多数情况下,知识以文本等抽象形式呈现,不能直接用于技术流程。因此,为了在技术流程中使用这些信息,需要对抽象知识进行审查或技术准备。在 PEGASUS 项目中,法律、标准和指南在数据处理步骤中被分析以定义测试对象的场景。标准和指南用于例如定义不同场景参数的最小和最大允许值。此外,这些信息源用于创建运营设计域 (ODD) 的共同理解。这是合理的,特别是如果测试对象应该在不同的国家/地区发布。因此,抽象知识是描述和定义场景的宝贵来源,具有基于知识的系统方法。这将在以下过程步骤中进行:系统识别场景 (4)。
系统识别场景 (4) 流程步骤使用先前提到的数据容器中的抽象知识 (1) 作为输入源,为数据库系统地生成场景。在项目中,这些过程步骤应用了不同的方法。示例包括基于本体的场景生成,它使用指南的知识组合式地确定所有可能的场景。另一个例子是识别自动化风险。通过这种方式,可以找到新的场景,它们是引入自动驾驶功能的原因。这两种方法都直接生成逻辑场景。另一个分析的识别逻辑场景的方法是基于专家方法,它可以识别测试对象周围会导致事故的场景。通过系统知识识别场景的过程步骤,PEGASUS 方法可以找到大量可能的场景。在知识发生变化的情况下,例如新的或更新的法律,需要生成更新的可能场景集。为了实现这一点,需要以自动方式生成这些场景。因此,这是 PEGASUS 数据驱动方法的一个有价值的扩展,将在下面进行解释。
除了抽象知识,另一个信息源是现有的测量数据,它用于 PEGASUS 方法中的数据驱动方法。项目中的数据基于真实测试驾驶、模拟、模拟器研究、现场操作测试 (FOT)、自然驾驶研究 (NDS) 或事故数据。这些来源包含不同类型的信息,并在 PEGASUS 方法中以不同方式使用。例如,事故数据用于生成与 ODD 内人类驾驶员相关的自动驾驶功能的有效性值。通过自然驾驶研究 (NDS),可以在不同场景中比较自动驾驶功能和人类驾驶员。测试驱动、FOT 或随机模拟是预先执行的场景,带有记录的数据。因此,使用这些信息源描述了一种数据驱动的方法来定义用于验证和验证的场景。
使用不同类型的数据面临的挑战是不同的格式,尤其是不同的数据表示方式。因此,在以下过程步骤中将数据转换为通用格式以在场景数据库中使用它是必要的。在 PEGASUS 方法中,这将在接下来的预处理/重建 (5) 过程步骤中完成。
预处理/重建 (5) 过程步骤用于将先前记录的数据转换为数据库的通用输入数据。因此,定义一个包含所有重建场景数据库中场景所需数据的通用格式是必要的。格式将在有关数据库的小节中进一步解释。定义数据库的输入格式后,来自不同来源的数据,例如来自不同 OEM 的记录数据,必须转换为通用输入格式。当无法直接转换时,这也可能包括基于模型的重建。此步骤之后,来自每个可用数据源的记录数据可以转换为通用格式并在数据库中处理。
总之,数据处理过程步骤在 PEGASUS 方法中具有两个主要目标。第一个目标是系统地生成逻辑场景,这些场景直接包含在数据库中。第二个目标是将已记录数据或先前执行的场景预处理并重建为数据库的通用输入格式。
需求定义 (1,3, 6)
PEGASUS 方法的“需求定义”步骤分为三个部分:数据容器(包含知识)(1)、包含需求分析的过程步骤(3),以及包含用于 HAD 评估的过程指南和指标的数据容器(6)。
抽象知识的数据容器 (1) 与上一节解释的容器相同。除了已经提到的信息源之外,测试对象所在国家或地区的法律法规、相关标准(例如 ISO 26262、SOTIF等等)或伦理委员会的结果(德国联邦交通部和数字基础设施部任命的自动驾驶和互联驾驶伦理委员会,2019 年)都作为信息源用于定义测试对象的需求。与之前解释的数据处理步骤类似,抽象知识无法直接用于技术流程。将抽象知识转换为技术可用的格式的准备工作将在下一个过程步骤——需求分析 (3) 中进行。
过程步骤需求分析 (3) 使用抽象知识为自动驾驶功能或一般测试对象定义技术可用的需求。因此,PEGASUS 方法目前应用两种方法。一方面,分析了一种基于社会接受标准的方法。为此,检查来自其他领域(例如铁路或核电站)的社会接受度,以评估这些领域可能转移给自动驾驶功能。目标是找到或定义与这些成熟技术类似的需求,用于自动驾驶功能。另一方面,执行基于风险的方法进行评估。因此,应用了计算风险的不同方法。一个例子是一种估计每个场景的驾驶需求以处理这些场景的方法。此过程步骤的结果是定义不同的需求和证明指南,可以在以下技术过程步骤中使用。
测试对象评估的需求存储在以下数据容器 (6) 中。该容器包含基于分析的抽象知识的指标,用于 HAD 评估和后续过程步骤的过程指南。一方面,结果用于数据库中的下一个步骤,将通过/失败标准集成到不同的场景中。另一方面,结果作为以下过程步骤(例如自动驾驶功能评估)的指南。
总之,PEGASUS 方法的需求定义具有基于不同抽象知识定义自动驾驶功能需求的总体目标。结果是用于 HAD 评估的过程指南和指标。
数据库 (7, 8, 9, 10, 11)
元素数据库由三个数据容器和连接这些数据容器的三个连接过程步骤组成。数据库的输入数据是之前执行的元素需求定义和数据处理的结果。数据库的一个目标是处理来自不同信息源的所有收集的测量数据。
此外,另一个目标是基于逻辑场景创建一个逻辑测试用例空间,用于测试执行,这是下一个元素——高度自动驾驶功能评估的主要输出。
数据库使用预处理和重建的测量数据作为输入,这些数据在之前执行的步骤 (5) 中已转换为 PEGASUS 数据格式。该格式包括有关信息,包括但不限于自我车辆状态、周围物体和车道信息,例如曲率、车道宽度等。为了在数据库中对测量数据应用指标和统计数据,PEGASUS 数据格式定义了许多信号和坐标系,以通用格式描述处理后的测量数据。为了在数据库中进一步使用数据,所有信号都需要满足要求,例如同步采样率。
在数据库中,应用不同的指标将 PEGASUS 格式的测量数据映射到预定义的逻辑场景,例如前车挑战者。因此,映射指标将测量数据分成不同的时间片段并将其排序到逻辑场景中。时间片段也用于提取最小和最大参数值,以根据真实测量数据描述逻辑场景中的参数范围。此外,还提取用于描述场景参数概率分布的参数。因此,可以根据 PEGASUS 方法中以下过程步骤的不同信息源 (2) 为预定义场景和来自系统识别的场景设置参数分布和范围,并使用真实存在的参数分布和范围。此外,用于计算单个场景的关键性的指标被应用并存储在各自的逻辑场景中。此外,上面提到的用于计算场景需求的指标也在此处应用,将信息添加到逻辑场景中。
先前执行的过程步骤 (8) 的结果存储在逻辑场景数据容器 (9) 中。逻辑场景的来源首先是系统识别场景的结果,其次是基于专家知识的预定义场景。逻辑场景代表一个模型,用来描述测试对象周围的环境,以及描述参数的范围和分布。这些逻辑场景基于一个六层模型(道路、基础设施、临时影响、可移动物体、环境条件、数字信息)进行描述。它还解释了描述可移动物体行为、彼此之间的交互以及转换为 OpenDRIVE 和 OpenSCENARIO 格式的技术转换的可能性。将场景转换为这些格式是必需的,例如在进一步的流程步骤中在模拟中执行场景。
在数据库中 PEGASUS 方法的下一个步骤中,生成一个逻辑测试用例空间,其中包括通过/失败标准以及额外准备,用于将现有数据准备为测试用例衍生。因此,逻辑测试用例包括逻辑场景加上评估标准。评估标准在过程步骤集成通过/失败标准 (10) 中添加到逻辑场景中。这些标准通过指标(例如 TTC、THW 等)及其阈值来表示。此过程步骤的信息是需求定义的结果,其中定义了用于 HAD 评估的不同指标 (6)。此外,基于需求定义的结果设置了测试用例中不同指标的阈值。
集成通过/失败标准 (10) 的过程步骤的结果存储在逻辑测试用例数据容器 (11) 中。该容器包括基于所有可用信息源 (1,2) 与自动驾驶功能或一般测试对象相关的测试用例。测试用例存储在技术格式 OpenDRIVE、OpenSCENARIO 和用于逻辑场景参数化的格式中。用于评估逻辑场景的指标存储在外部脚本中,用于以下过程步骤的应用。有了这些信息,就可以执行以下的基本元素——高度自动驾驶功能评估。
总之,数据库是 PEGASUS 方法中的一个关键元素,因为它将 PEGASUS 方法的准备部分(需求定义和数据处理)与执行部分(高度自动驾驶功能评估)连接起来。数据库的一个主要目标是将测量数据映射到逻辑场景。因此,这些逻辑场景在数据库中进行管理,包括基于特征关键字的过滤和排序功能。此外,另一个任务是基于逻辑场景和指标生成逻辑测试用例,作为以下过程步骤的输入。
高度自动驾驶功能评估 (12, 13, 14, 15, 16, 17, 18, 19)
高度自动驾驶功能评估步骤由四个数据容器和四个连接这些数据容器的连接过程步骤组成。评估的输入数据是之前执行的元素需求定义和数据库的结果。该元素的主要目标是基于逻辑测试用例空间的测试用例派生、测试执行、测试评估以及最终生成的证据发布。该过程步骤通过利用过程指南的需求定义结果得到支持。结果是对最终将证据与安全论证进行比较的安全声明的贡献。
高度自动驾驶功能评估的第一步是应用测试概念,采用各种变分方法。此过程步骤的输入首先是逻辑测试用例 (11),其次是来自数据容器流程指南 (6) 的流程指令。在此过程中,应用不同的变分方法将逻辑测试用例转换为可执行的具体测试用例。这意味着变分方法例如使用随机算法从参数分布和范围中选择具体值,为每个场景参数创建具有具体值的具体测试用例。这使得可以在不同的测试工具(例如模拟器、实验场或真实世界测试)上执行单个测试用例。此外,测试概念将单个测试用例分配到上述不同的测试环境中。
上一个过程步骤的输出是单个具体的测试用例。在 PEGASUS 方法中,具体测试用例通过数据容器 (13) 中的 OpenDRIVE、OpenSCENARIO 技术格式和用于评估测试数据的指标脚本表示。每个具体测试用例的参数范围和分布都被具体值取代。测试用例将在下一个过程步骤测试执行中执行。
在下一个过程步骤中,具体测试用例将在模拟器和实验场 (15) 上执行,辅以真实世界测试。为此,识别由自动驾驶功能测试引起的测试执行需求。因此,根据识别的需求改进了不同的模拟环境。此外,为了从模拟中获得更真实的测试数据,开发了不同类型的模拟模型(例如传感器模型或交通模型)并将其集成到测试执行中。为了简单地交换模拟工具和模型,使用了新的接口,例如开放模拟接口 (OSI)。同样,为了获得更具确定性的测试执行,开发了用于实验场测试的新工具。示例包括从模拟器直接链接到实验场基础设施以比较这两个结果,或新一代交通模拟车辆。这些是自动驾驶的真实车辆,根据预定义的轨迹在实验场行驶。因此,可以确定性地测试各种场景。另一种测试执行方式是真实世界测试,测试对象在真实交通中进行测试。在这种情况下,直接执行具体场景是不可能的。因此,PEGASUS 方法将提供测试条件指示,以便在接近具体场景的条件下执行测试。
测试用例执行结果存储在数据容器测试数据 (15) 中。测试数据以信号痕迹的形式描述测试执行的信息。这些信号的格式与 PEGASUS 格式中的数据相同 (7)。因此,可以将测试数据作为 PEGASUS 方法的额外输入。
在方法的下一个过程步骤 (16) 中,测试数据使用不同的指标(例如 TTC 或距离检查)进行评估,并分类为碰撞等组。基于测试结果,该过程步骤启动一个迭代评估,其有两个目的。一方面,测试结果被传回随机变分 (13),以便根据上次测试结果在逻辑场景的参数空间中找到更关键的场景。另一方面,测试结果用于识别具体场景,这些场景用于在其他测试实例(例如实验场测试)上进行交叉验证。如果结果满足某些标准,迭代评估过程会中断,评估后的测试结果存储在以下测试结果数据容器中。
数据容器测试结果 (18) 包含不同测试运行的评估结果。测试结果被描述为记录的测试执行过程信号痕迹。此外,指标评估的结果也添加到痕迹中。此外,可以用时间戳标记不同指标的最大和/或最小值。测试结果将在以下过程步骤中用于风险评估。
风险评估 (18) 过程步骤对单独执行的测试用例进行额外评估。此过程步骤与之前在过程步骤 (16) 中执行的测试评估之间的区别在于评估的重点。与上次评估不同,这次评估的目的是确认测试对象是否符合预定义的行为标准。因此,使用与过程步骤 (16) 中不同的指标评估单个测试用例。在特定的 PEGASUS 背景下,预定义标准例如保持适当的安全距离、不发生碰撞以及尽可能减轻碰撞,因为它们符合测试概念。在风险评估期间,对于每个标准,都会进行评估,判断 HAD 是否符合该标准。根据每个标准的结果,提出了一种方法来决定单个测试用例是否相对于预定义的行为标准通过或失败。在 PEGASUS 方法中,风险评估的结果存储在带有安全声明的数据容器中。
安全论证 (20)
PEGASUS 方法的最后一步是结合生成的安全声明应用安全论证。PEGASUS 安全论证被理解为一个概念框架,通过结构、形式化、一致性、完整性和相关性,支持确保和批准更高等级的自动化。它的结构是通过引入五个层次来实现的。在描述每个层次的元素时,尽可能使用已建立的形式化方法,例如目标结构符号。这些元素在各个层次之间相互关联,形成一个连贯的论证。还建议评估每个元素的完整性,以建立可靠的安全论证。PEGASUS 安全论证的核心假设是:如果一个按照 PEGASUS 安全论证框架提出的论证链经得起严格审查,那么它将支持确保和批准更高等级的自动化。
总之,PEGASUS 方法描述了用于自动驾驶功能的基于场景的验证和验证方法的系统概念。通过方法的核心元素,包括需求定义、数据预处理、数据库中的信息存储和处理、自动驾驶功能评估,以及最终的安全论证,PEGASUS 项目从随机测试特征的距离-基于方法迈出了第一步,转向了系统性的基于场景的 V&V 方法。然而,该项目也显现了两个重要发现:仍有许多问题悬而未决,并且不断涌现新的研究问题。然而,PEGASUS 方法有可能在未来验证和验证活动的大局或总体架构中对这些悬而未决和新产生的研究问题进行排序。
(欢迎申请加入智能驾驶交流学习群,加小编微信号zhijiashexiaoming)