Occupancy Network并非特斯拉发明,最先提出Occupancy Network的是2018年的论文《Occupancy Networks: Learning 3D Reconstruction in Function Space》,主要作者是Tubingen大学和博世旗下软件公司ETAS。更早可以追溯至2012年的论文《Indoor Segmentation and Support Inference from RGBD Images》,主要作者是纽约大学。而最早可以追溯到1986年的论文《A computational approach to edge detection》。Occupancy Network源自语义分割,语义分割需要连续边界而不是传统的Bounding Box(一般会缩写为BBox),语义分割再加上2D或3D重建,就是Occupancy Network。不过让Occupancy Network扬名天下的是特斯拉。
目前,传统的3D目标感知算法缺点是过于依赖数据集,但数据集的分类有限,通常不超过30类,总有不常见的物体类别没被标注,这些未被标注的物体再次出现在实际场景中,会因为数据集中没有标注,无法识别而被感知系统忽略掉,导致车辆不减速直接撞向物体。这种事故经常发生,最典型的是当车辆有故障,驾驶员下车站在车尾,打开后备箱找维修工具,对于计算机视觉来说就是一个难题,这是个打开的后备箱加人的影像,或者人推着电动车或自行车过马路,人眼可以一眼看出,但机器就彻底傻眼,复合目标,从未被标注的物体或从未出现在数据集的物体,要探测目标距离,必须先识别目标,探测和识别是一体的,无法分割,画出BBox,机器无法识别,画不出BBox,会认为前方没有物体,自然不会减速,直接撞上去。
BBox的致命缺陷,一是无法忽略掉物体的几何细节,二是探测和识别一体,遇到未被标注的物体就会视而不见。Occupancy Network就是为了解决BBox的缺陷而产生的,Occupancy Network学术上讲就是建模物体详细几何和语义的通用且连贯的表征。一个需要从输入图像中联合估计场景中每个voxel的占据状态和语义标签的模型,其中占据状态分为free,occupied和unobserved三种,对于occupied的voxel,还需要分配其语义标签。而对于没有标注的物体类别,统一划分为General Objects(GOs),GOs少见但为了安全起见是必须的,否则检测时经常检测不到。Occupancy Network理论上能解决无法识别物体的难题,但实际中不能。很简单,Occupancy Network是一种预测性质的神经网络,它不可能达到100%的准确度,自然也就有漏网之鱼,还是有无法识别的物体无法探测。
占用网络算法排名,第一名是英伟达的FB-OCC,小米和北大联合的UniOcc排名第三,华为仅排名第六。目前基于BEV的解决方案很多。这些解决方案在经过一定的修改后都可以适用于 3D occupancy 预测,门槛不高。
目前Occupancy Network准确度有多少呢?目前最顶级的Occupancy Network的mIoU是54.19%。mIoU是预测值与真值的交并比,某种意义上可以看做是准确度。这和传统激光雷达语义分割差距极大,2021年的激光雷达语义分割就能达到80%以上。
另一份资料,OctreeOcc论文中提到,目前得分最高的是上海科技大学的OctreeOcc,也就是上表中的“Ours”。排名第二的是英伟达的FB-OCC,与OctreeOcc差距很小。
KITTI数据集3D语义场景完成的mIoU上得分最高的是鉴智机器人的OccFormer。
我们就来深入了解一下这OctreeOcc、FB-OCC和OccFormer三个模型。
先来看英伟达的FB-OCC,论文《FB-OCC: 3D Occupancy Prediction based on Forward-Backward View Transformation》,论文很简短,只有5页。
英伟达的FB-OCC非常简洁,基本上就是BEVFormer加了一个占用网络head。纯视觉的3D感知模型的核心模块是 view transformation 模块。这个模块包括两个主要的视图转换方式:正向投影(LSS)和反向投影(BEVFormer)。FB-BEV 提供了一个统一的设计,利用这两种方法,扬长避短。在FB-OCC中,使用前向投影来生成初始的3D体素表征,然后将其压缩为一个扁平的 BEV 特征图。BEV特征图被视为BEV空间内的queries,并与图像编码器特征一起获得密集的几何信息。然后将3D体素表征和优化后的BEV表征的融合特征输入到后续的任务头中。
英伟达采用了预训练,通过深度估计任务增强模型的几何意识。英伟达对nuScenes数据集进行了广泛的预训练,主要集中在深度估计上。值得注意的是,深度预训练缺乏语义层面的监督。为了减轻模型过度偏向深度信息的风险,可能导致语义先验的损失(特别是考虑到模型的大规模特性,容易出现过拟合),在进行深度预测任务的同时,也要致力于预测二维语义分割标签,如上图3所示。
OccFormer以单目图像或环视图像作为输入,首先由图像编码器提取多尺度特征,然后基于深度预测和体素Voxel池化得到三维场景特征。随后,该三维特征首先经过dual-path transformer encoder进行三维视角下的特征提取,得到多尺度体素特征。最终transformer occupancy decoder融合多尺度特征,预测不同类别的binary mask并结合得到最终的occupancy预测。
图像编码器的输出为输入分辨率的 1/16 的融合特征图: 来表示提取的特征。
然后是英伟达提出的LSS BEV算法,编码后的图像特征被处理以生成 context feature
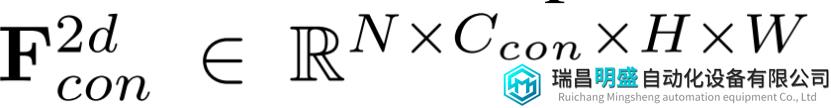
N 是相机视角的数量,C是通道数,(H,W) 代表分辨率。
离散的深度分布是
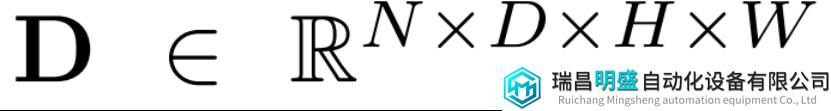
二者相乘得到点云的表示:
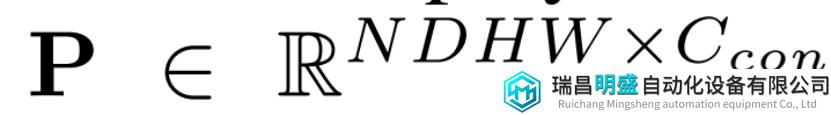
最终进行体素池化以创建三维特征 3D feature volume

其中(X, Y, Z) 表示三维体的分辨率。
由于驾驶场景中沿着水平方向的信息变化最剧烈,而高度方向上信息密度相对较低,因此三维特征编码的重点应该放在水平方向上。但由于occupancy需要三维的细粒度信息,将三维特征完全压平进行处理是不可取的。输入的三维特征会经过局部和全局两条路径、沿着水平方向进行语义特征提取,两条路径的输出会通过自适应融合得到输出的三维场景特征。对于输入的三维特征,局部 local 和全局 global 路径首先沿水平方向并行地聚集语义信息。接下来,双路径输出通过 sigmoid-weighted 进行融合。局部路径主要针对提取细粒度的语义结构。由于水平方向包含最多的变化,通过一个共享编码器并行处理所有BEV切片能够保留大部分语义信息。将高度维度合并到批处理维度,并使用窗口化自注意力作为局部特征提取器,它可以利用较小的计算量动态地关注远距离区域;另一方面,全局路径旨在高效捕获场景级语义布局。为此,全局路径首先通过沿高度维度进行平均池化来获取BEV特征,并采用相同的窗口化自注意力实现特征提取,为了进一步增大全局感受野,还使用了ASPP结构来捕获全局上下文。
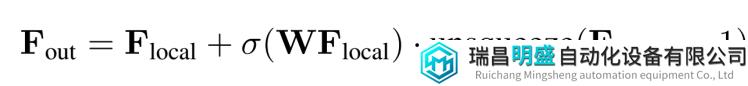
W指的是沿高度维度生成聚合权重的 FFN;σ(·) 是 sigmoid 函数;“unsqueeze” 是沿高度方向扩展全局 2D 特征。
语义分割方面采用了META提出的Mask2Former ,Mask2Former建立在一个简单的元框架 (MaskFormer)和一个新的 Transformer 解码器上,其关键组成部分为掩码注意力(Masked-attention),通过将交叉注意力限制在预测的掩码区域内来提取局部特征。与为每个任务(全景、实例或语义)设计专门模型相比,Mask2Former 节省了3倍的研究工作,并且有效节省计算资源。Mask2Former 在全景分割(COCO上的 57.8 PQ)、实例分割(COCO 上的 50.1 AP)和语义分割(ADE20K 上的 57.7 mIoU)上都实现了SOTA。
利用输入的多尺度体素特征 (multi-scale voxel features) 和参数化的查询特征 (parameterized query features) ,transformer decoder 对查询特征进行迭代更新,以达到预期的类别语义。在每个迭代内,查询特征 (queries features)Q1, 通过 masked attention 来关注它们相对应前景区域。
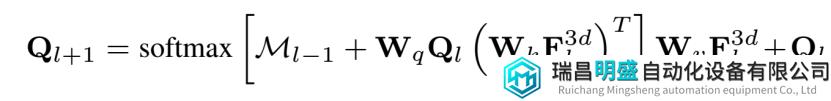
然后进行 self-attention,以交换上下文信息,然后用FFN进行特征投影。在每个迭代结束时,每个Q1被投影来预测它的语义分对数 (semantic logits)Pi,和掩膜嵌入 (mask embedding)εmask,后者通过 一个 per-voxel 嵌入εvoxel和 sigmoid 函数的点积进一步转化为二进制的三维掩膜Mi。
OctreeOcc框架
OctreeOcc框架如上图, 实际就是用传统的八叉数空间表示法取代了传统的BEV或Voxel。
不过目前这些前沿试验性质的论文都无法落地。
左边的是Occ3D-nuScenes,专为占用网络测试搞的数据集,右边的是KITTI的语义分割测试数据集,占用网络模型消耗内存惊人,最少都需要25GB,对运算资源消耗惊人,即便是用英伟达8张A100,最快的也要386毫秒,自动驾驶最低门槛10Hz都达不到。这个每帧都需要读出模型一次,也就说需要容量至少超过48GB的高宽带存储,最好是HBM3,GDDR6都非常勉强,而HBM价格惊人,英伟达H100的HBM内存容量也不过80GB。
无人驾驶,前路漫漫,任重而道远。