Memory consistency model又称Memory model (内存模型),定义了使用Shared memory(共享内存)执行多线程(Multithread)程序所允许的行为规范。Memory model定义了软硬件接口规范,以便程序员预料硬件的行为、硬件实现者知道可以使用什么样的优化,消除软硬件在配合上的歧义。
1、共享内存的问题
为什么需要定义内存模型规范,我们先举个例子:系统中有两个cores在执行各自的代码,假设所有变量的初始值都是0,那么最终Core C2中寄存器r2的值应该为多少呢?
表1 寄存器r2的最终值为多少?

大多数程序员会期望Core C2的寄存器r2应该得到NEW值。然而,如今一些计算机系统中,最终寄存器r2的值可能是0。因为S1 store和S2 store访问不同的地址,硬件可能会对Core C1的S1 store和S2 store重排序,从而使得S2先于S1写到memory中。接下来,Core C2读取到Core C1的S2 store更新的flag值NEW,以为Core C1已经准备好了data值,就发起L2 load读取data返回给寄存器r2,而此时data值为0,也就导致最终寄存器r2为0。如下表2所示,程序的执行总顺序是S2->L1->L2->S1。
表2 程序的一种可能执行结果

对于相同地址的memory访问,硬件需要保证它们按照程序顺序(program order)执行,但硬件会对不同地址的memory访问进行重排序(Reorder),根据重排序的memory操作是load还是store,分为四种情况:
Store-store reorder:如果Core有一个非FIFO类型的write buffer,它允许store以不同于它们进入的顺序离开,那么两个store可能会被重新排序。比如第一个store在cache中miss,而第二个store hit cache,又或者第二个store与更老(older)的store合并(merge)到同一个write buffer的条目中。Store-store重排序对单线程执行没有影响。对多线程就会出现表1的现象。
Load-load reorder:Core的动态调度可以不按program order执行指令。如果表1中,Core C2可以乱序执行L1 load和L2 load。对于单线程执行,这种不同地址的重排序是安全的。但多线程中,Core C2的load重排序与Core C1的重排序store情况相同,如果memory按照L2->S1->S2->L1的顺序执行,那么寄存器r2将被赋值为0。
Load-store reorder:乱序执行的Core可以重排序来自同一线程不同地址的load和store指令。用年轻的(younger)的store重排序到较老(older)的load之前(load-store reorder)可能会导致不正确的行为。如果younger store是互斥锁(mutex)的解锁操作,那么被reorder的older load可能load到解锁之后的其它值。
Store-load reorder:如果将younger的load重排序到older的store之前,就如表3所示,可能会出现反直觉的结果r1和r2都是0。这种情况通常是系统中实现了FIFO类型的write buffer引起的。就比如Intel和AMD的x86系统。
表3 r1和r2可以同时为0吗

与单线程执行不同,多线程执行通常允许多个正确的行为,这种执行结果的不确定可能会让大家感觉困惑,但所有当今的多Core在默认情况下都是非确定性的,所有体系结构(architecture)都允许并发线程的多重交错执行。不过我们平时使用的软件会有适当的同步操作来将这些不确定性转成确定性的结果。因此,必须精确地定义memory model,减少这些不确定带来的影响。
2、Memory consistency model标准
2.1 4P原则
一个好的Memory consistency model应该具备以下4P原则:
Programmability:好的模型应该使编写多线程程序变得相对容易,而且对于大多数用户来说是直观的。
Performance:好的模型应该在合理的功耗、成本等条件下促进更高性能的实现,也应该给予实现者广泛的选择余地。
Portability: 好的模型应该被广泛采用,或者至少提供向后兼容或模型之间的转换能力。
Precision:好的模型应该是能用数学公式精确定义的。自然语言描述太过模棱两可,通常会让受用者无法达到允许的极限。
2.2 Memory consistency model和cache coherency的联系和区别
之前的另一篇文章解释了cache coherency原理,需要的请翻看《一文读懂Cache一致性原理》。Cache coherency和memory consistency很容易混淆,看似cache coherency定义了共享内存(Shared memory)的行为。但事实并非如此,从图1可以看到,coherency协议只是为core pipeline提供了一个内存系统(Memory system)的抽象,它本身不能决定共享内存的行为,反之,core pipeline也不能。
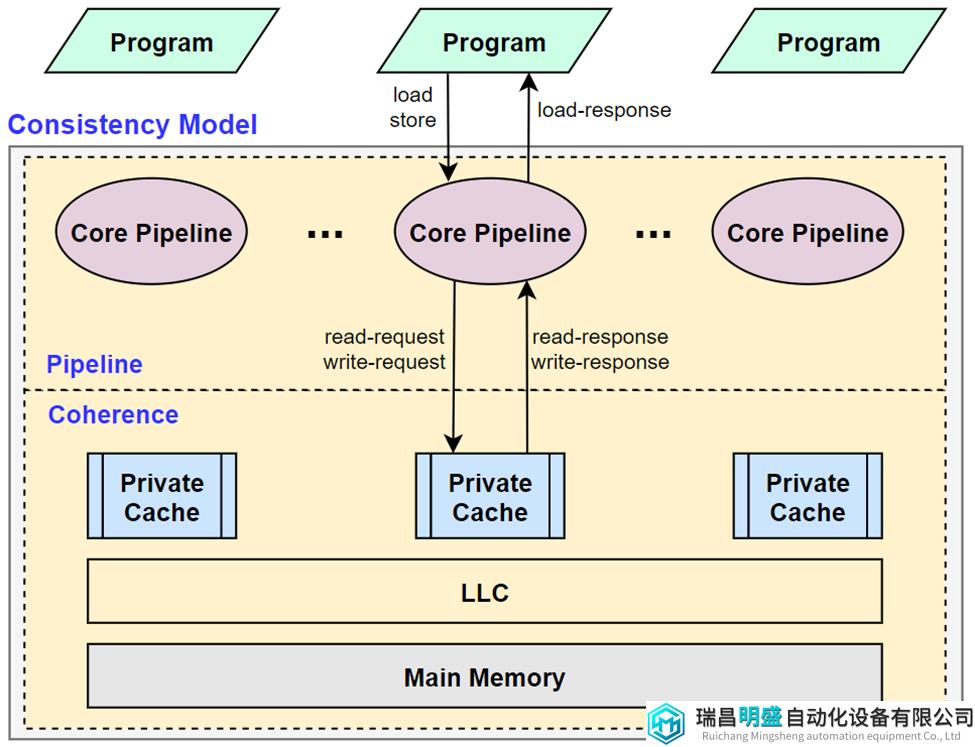
图1 consistency model
如果core pipline以与program order相反的顺序将memory操作重排序并送给coherency协议,即使coherency协议正确地完成了它的工作,共享内存也会发生问题。总结来说:
Cache coherency不等于Memory consistency。Memory consistency是由core pipeline和cache coherency共同实现的,共同定义了共享内存的行为。
Memory consistency的实现可以把cache coherency当作是一个黑盒子。
3、概念解释
为了方便大家的理解,本小节讲述了memory consistency中常见的几个概念。
Program order(程序顺序):是指程序内语句的顺序执行,这意味着语句将按照它们在代码中编写的顺序依次执行,除非遇到循环、条件或函数调用等控制流结构改变了执行流。
Memory order(内存顺序):是指系统中处理器(单个core或多个cores)的各个操作对内存进行访问的总顺序(total order)。
Single processor (core) sequential:是指任意指令的执行结果与按照程序指定的顺序执行的操作相同。
Multiprocessor sequentially consistent:是指任意执行的结果都是相同的,所有处理器的操作都按照某种内存顺序执行,并且每个处理器的操作按照其程序指定的顺序出现在内存顺序中。
Load:从memory中读取数据到寄存器。
Store:将寄存器数据写到memory中。
RMW:为了编写多线程代码,程序员需要能够同步不同线程,而这种同步通常需要执行成对的原子操作。这个功能是由原子执行的“read-modify-write” (RMW)指令提供的,例如:“test-and-set”, “fetch-and-increment”和 “compare-and-swap”。这些原子指令对于正确的同步至关重要,并用于实现spin-locks(自旋锁)和其它同步场景。比如spin-lock,程序员可以使用RMW来原子地读取锁的值是否为未锁定(等于0),并写入锁定的值(等于1)。
FENCE:执行FENCE可以确保program order在FENCE之前的memory操作先于比在FENCE之后的memory操作到达memory order上的。因此,FENCE也叫memory barriers。FENCE在SC模型中是不需要的,在TSO和relaxed模型中才需要的。不过TSO模型的程序员很少使用FENCE,因为TSO在大多数场景下不需要FENCE。但是FENCE对relaxed模型有重要作用。
Processor consistency:简称PC,表示一个Core的store操作按顺序达到其它Core,但不一定同时达到其它Core。TSO模型是PC的特殊情况,其中每个Core都可以立即看到自己的Store操作,但是当任何其它Core看到Store操作时,所有其它Core都可以看到它,这个属性称为write atomicity。
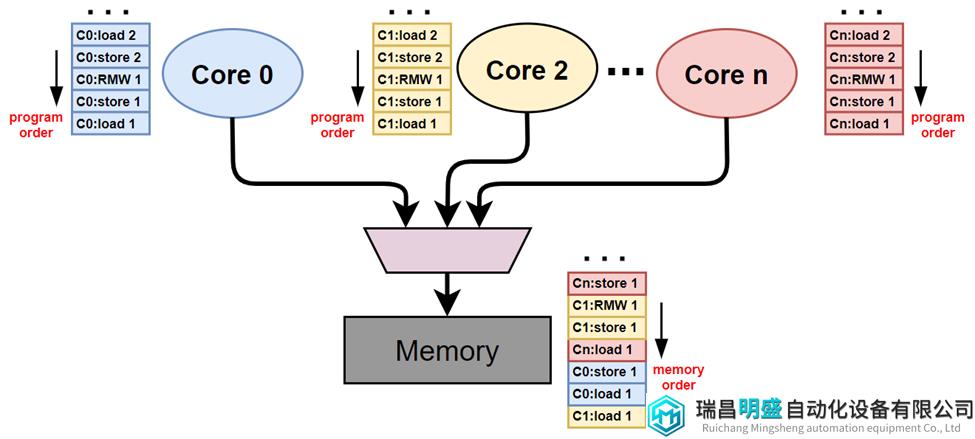
图2 memory system
关于load和store在program order和memory order上出现的位置可以用下图3方式来展示。中间垂直向下的箭头表示memory order (<m),而每个Core的向下箭头表示其program order (<p)。op1<m op2意味着在memory order上,op1在op2之前。类似的op1<p op2意味着在Core的program order中,op1在op2之前。在Sequential Consistency (SC,下文会详细介绍)中,memory order保留每个Core的program order。“保留”是指op1<p op2意味着op1<m op2。注释中的值(/* … */)为load或store的值。
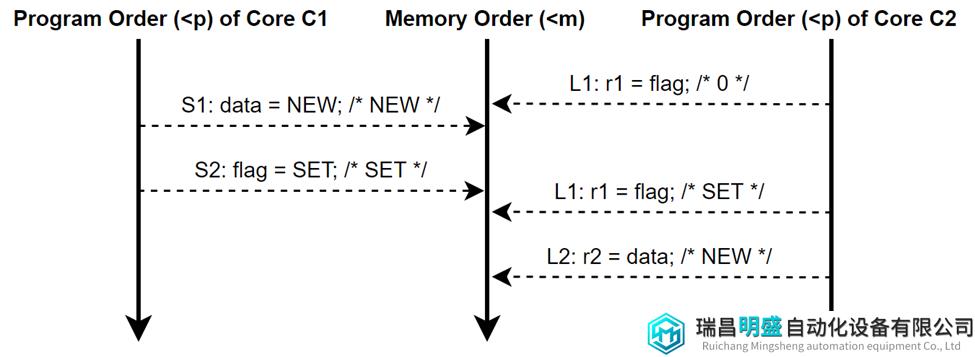
图3 执行流表示
4、Memory consistency model分类 –
Memory consistency model主要可以分为Strong model和Relaxed model两大类,如下图4所示为常见的memory model。
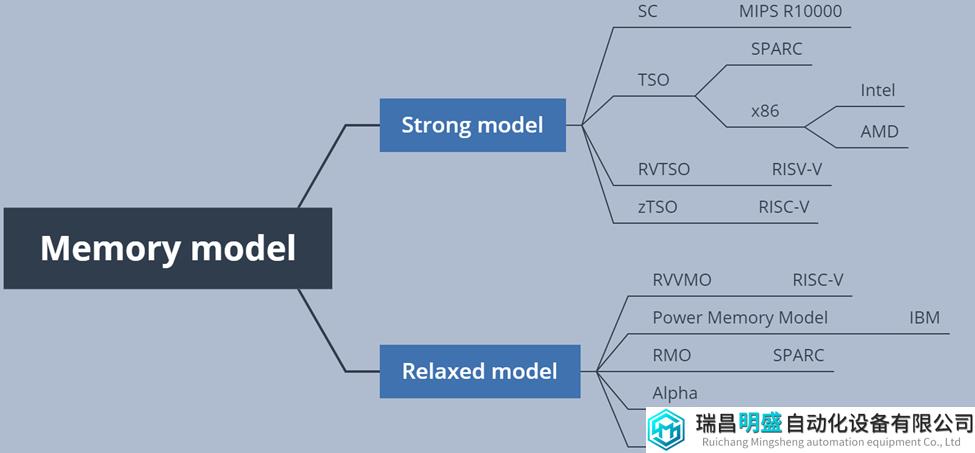
图4 常见memory model
一般来说,memory models之间是relaxed(weaker)还是stronger可以这样判断:如果所有model A里允许的行为也是model B里允许的行为,则model B比model A更relaxed(weaker),反之则不然。如果model B比model A更relaxed,那么所有的model A实现也是model B实现。当然也有可能两个memory models无法比较,因为它们各自都有对方不允许的行为。
在Strong model里,常见的有SC (Sequential Consistency)和TSO (Total Store Order)两种,这两种models的global memory order通常都保留每个线程的program order。我们平时常见的Intel和AMD的CPU就是采用TSO模型的。Relaxed model也包括很多种类的models,终端设备中大量使用的Arm CPU就是采用Relaxed model。Relaxed model只保留程序员需要的顺序,这种方法的主要好处是允许更多的硬件和软件(编译器和运行系统)优化,减少排序约束可以促进性能的提高。主要缺点是,当需要在某些访存操作间排序时,relaxed model必须为程序员或低层次软件提供排序的通信机制,而供应商未能就relaxed model达成一致,损害了代码的可移植性。
5、SCmodel –
Sequential consistency (SC)模型是最直观的memory model,它是程序员对共享内存的预期行为,并为理解其它memory model提供了基础。在SC模型中,memory order保留了每个core的program order。也就是SC模型为同一个线程的两个指令间的所有四种load和store组合(Load -> Load, Load -> Store, Store -> Store, and Store -> Load)保留了顺序。
5.1 SC模型举例
图5以表1中的代码为示例。
表1 寄存器r2的最终值为多少?

图5 表1程序的SC执行
在图5中,两个Core的执行以Core C2寄存器r2的值为NEW结束。唯一的不确定性是Core C2 L1在load值SET之前读取flag为0的次数是多少,不过这一点不重要。
再以表3为例。
表3 r1和r2可以同时为0吗
在SC模型中,(r1, r2)的可能值有三种:(0, NEW),(NEW, 0)或(NEW, NEW)。
(r1, r2)为(0, NEW)的执行流:{S1, L1, S2, L2};
(r1, r2)为(NEW, 0)的执行流:{S2, L2, S1, L1};
(r1, r2)为(NEW, NEW)的执行流:{S1, S2, L1, L2},{S1, S2, L2, L1},{S2, S1, L1, L2},{S2, S1, L2, L1};
(r1, r2)为(0,0)的执行流:无;
图6画出了(r1, r2)为(NEW, NEW)的执行流的其中一种{S1, S2, L1, L2}。

图6 SC执行流
图7画出了一个非SC的执行流来做对比,在这种执行流中,(r1, r2)的值将为(0,0)。但对于这种结果,没有办法创建一个保留program order的memory order,因此不被SC模型所允许。
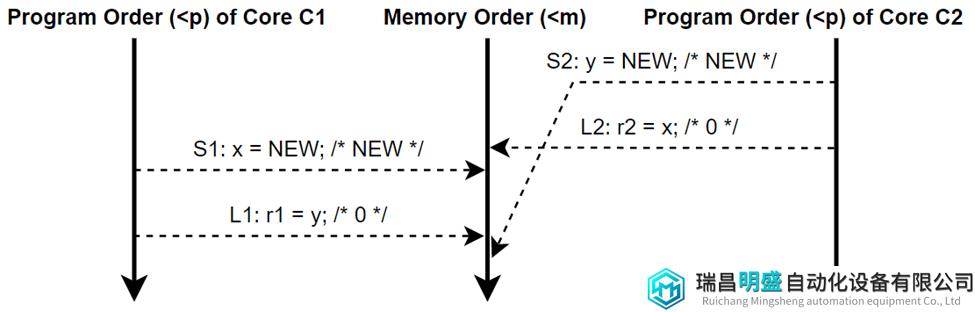
图7 非SC执行流
5.2 SC模型公式
L(a)和S(a)分别表示地址为a的load和store指令。<p和<m分别定义了program order和memory order。SC模型需要满足以下条件:
不论load或store指令是访问相同还是不同的地址(即a=b或a≠b),所有Cores按照program order将它们插入到memory order<m中。有四种情况:
如果L(a) <p L(b),那么L(a)<m L(b) /* Load -> Load */
如果L(a) <p S(b),那么L(a)<m S(b) /* Load -> Store */
如果S(a) <p S(b),那么S(a)<m S(b) /* Store -> Store */
如果S(a) <p L(b),那么S(a)<m L(b)
/* Store -> Load */
每次load得到的数据值都是从它之前(memory order)的最后一个相同地址的store获取到的。也就是L(a)的值等于MAX<m {S(a) | S(a)<m L(a)}的值,其中MAX<m表示memory order上的最新值。
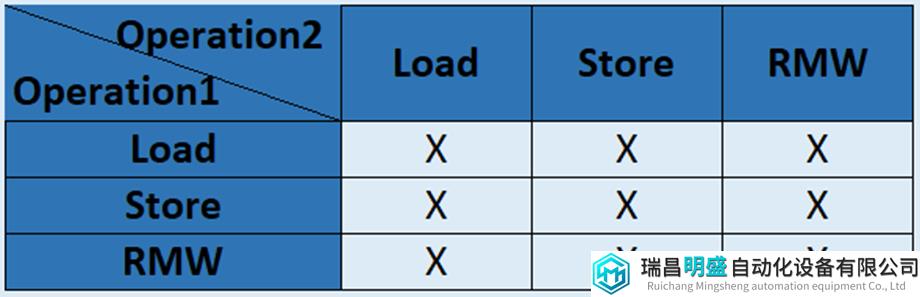
表4总结了SC模型的排序要求,这个表指定consistency model强制遵循哪些program order。如果一个给定的线程在program order的store之前有一个load(load是表中的”Operation1”,store是表中的”Operation2”),那么在交集的表项如果是一个”X”,表示对应的操作必须按program order执行。对于SC,所有的memory操作都必须按照program order执行的。对于RMW指令的执行必须是原子的,RMW的read(load)和write(store)操作必须连续出现在SC模型的memory order上。
表4 SC保序规则 (X表示必须遵循)
5.3 SC模型实现
如图8所示,SC模型可以用一组Core Ci、一个多选一选择器和一个Memory实现。假设每个Core按program order一次向选择器提供一个memory操作,选择器每次选择一个Core的操作,允许完成一次memory访问操作,再去选择下一个操作,并且只要Core存在请求就重复此过程。如果有多个Core同时请求,选择器可以通过任何方法(例如:随机)挑选Core。这就完成了一个简单的SC模型。
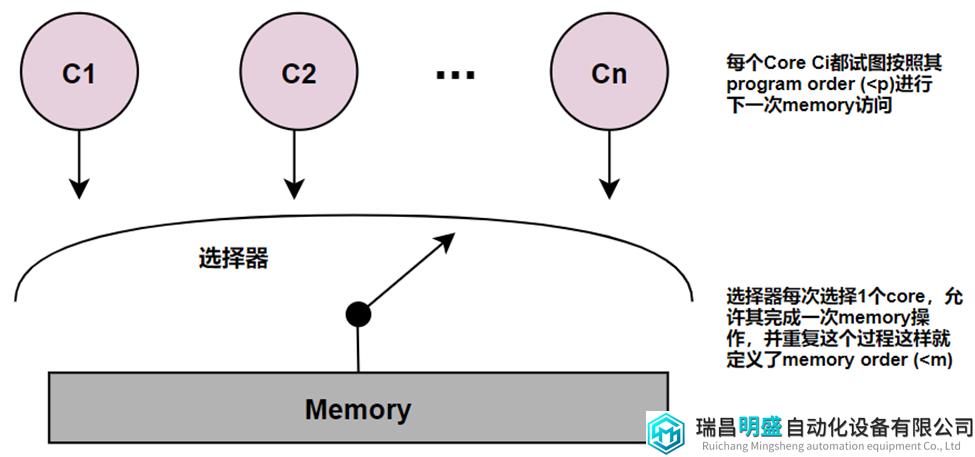
图8 简单的SC模型实现
6、TSOmodel
Total Store Order(TSO)是一个广泛使用的memory consistency model。TSO最初是由SPARC引入的,x86也是使用TSO模型。为了方便移植最初为x86或SPARC架构编写的代码,RISC-V也支持TSO扩展RVTSO。
6.1 为何引入TSO模型
处理器Core经常使用write(store) buffer来保存commited(retired)的stores指令,直到memory系统可以处理这些stores。当store commit时,它就进入write buffer,Core可以继续处理后续的指令,直到要写的cache line在cache中有读写权限,store从write buffer中退出来。因此,write buffer隐藏了处理器store miss cache下的latency(延迟)。
在单core处理器中,如果对地址A的store还在write buffer中,后续对地址A的load可以通过bypass方式来获取最近store的数据,其中最近的顺序是由program order决定的,从而使write buffer在体系结构(architecture)上不可见。但在多core处理器中,如果每个core都有自己的bypass write buffer,那么write buffer在体系结构上是必须可见的。以表5的代码为例,Core C1的S1和Core C2的S2假设都把store data暂放在write buffer中,最终会使得r1,r2都为0,但这种情况在SC模型中是不可能的。
表5 r1和r2会同时为0吗

如果去掉write buffer,会使性能下降,因此SPARC和后来的x86选择放弃SC模型,转而支持TSO模型。TSO模型允许在每个Core上使用FIFO类型的write buffer,它允许r1,r2都为0的结果。下图9为r1,r2都为0的TSO执行流。
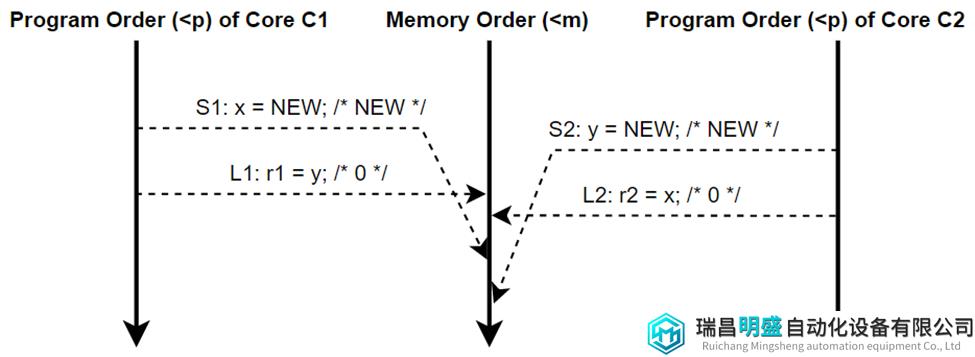
图9 TSO模型执行
6.2 TSO模型举例
在TSO模型中,Store->Load的memory order不需要保留program order,因此允许每个Core使用write buffer。由于TSO模型需要保留Store->Store的order,因此write buffer必须是FIFO类型的,而且不能合并多个store的数据。
TSO允许一些非直观的执行结果,表6是在表5的基础上修改的.其中Core C1和Core C2分别生成x和y的本地副本。许多程序员可能会假设,如果r2和r4都等于0,那么r1和r3也应该是0,因为store S1和S2必须在load L2和L4之后插入memory order中。
表6 r1和r3是否会被设置为0

但是,图10演示了一个执行流,其中r1和r3通过bypass获得了每个Core的write buffer中的NEW值。实际上,为了保持单线程顺序正确,每个Core都必须按照program order看到自己store的数据,即使其它Core还没有观察到该store的数据。因此,在所有的TSO模型执行中,本地副本r1和r3总是被设置为NEW值。
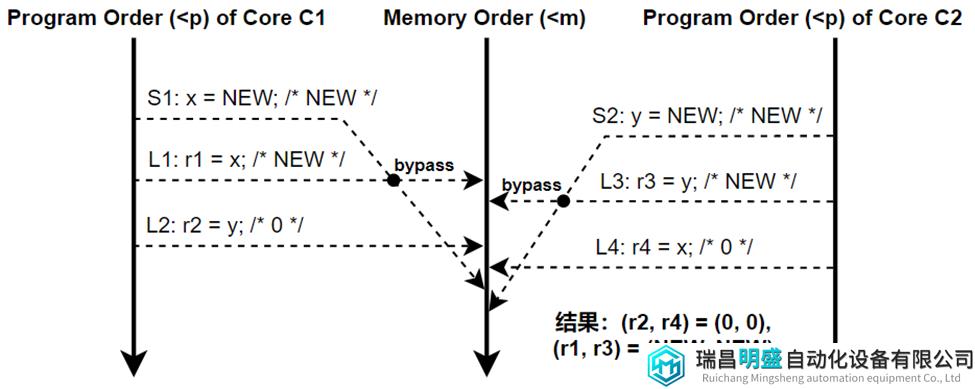
图10 程序的TSO执行 (带有bypass)
6.3 TSO模型公式
TSO模型执行需要满足以下条件:
不论load或store指令是访问相同还是不同的地址(即a=b或a≠b),所有Cores按照program order将它们插入到memory order<m中。有四种情况:
如果L(a) <p L(b),那么L(a)<m L(b) /* Load -> Load */
如果L(a) <p S(b),那么L(a)<m S(b) /* Load -> Store */
如果S(a) <p S(b),那么S(a)<m S(b) /* Store -> Store */
如果S(a) <p L(b),那么S(a)<m L(b) /* Store -> Load */
/* 修改点1:使能FIFO write buffer */
每次load得到的数据值都是从它之前(memory order)的最后一个相同地址的store获取到的。也就是L(a)的值等于MAX<m {S(a) | S(a) <m L(a) or <p L(a)}的值/*(修改点2:需要bypass)*/,其中MAX<m表示最新值。这一点表示load的值是同一地址的最后一个store的值,该store在memory order中处于它前面,或者在program order中处于它前面(通过write buffer来bypass)。
因为1)中Store->Load的memory order不被保证,所以TSO增加了FENCE指令,在程序员希望对Store->load进行排序的情况下,可以store和后续的load之间放置一个FENCE指令来显示指定排序关系。FNECE指令可以对任何操作进行保序。它的定义如下: /*(修改点3)*/
如果L(a) <p FENCE,那么L(a)<m FENCE /* Load -> FENCE */
如果S(a) <p FENCE,那么S(a)<m FENCE /* Store -> FENCE */
如果FENCE <p FENCE,那么FENCE <m FENCE /* FENCE -> FENCE */
如果FENCE <p L(a),那么FENCE<m L(a) /* FENCE -> Load */
如果FENCE <p S(a),那么FENCE<m S(a) /* FENCE -> Store */
除了Store->Load之外,TSO模型要求其它操作要自然保序。因此TSO模型的FENCE可以只定义以下属性:
如果S(a) <p FENCE,那么S(a)<m FENCE /* Store -> FENCE */
如果FENCE <p L(a),那么FENCE<m L(a) /* FENCE -> Load */
这里选择让TSO FENCE冗余地排序所有操作,这样也不会造成问题,并且可以使FENCE像下文Relaxed模型中定义的FENCE。
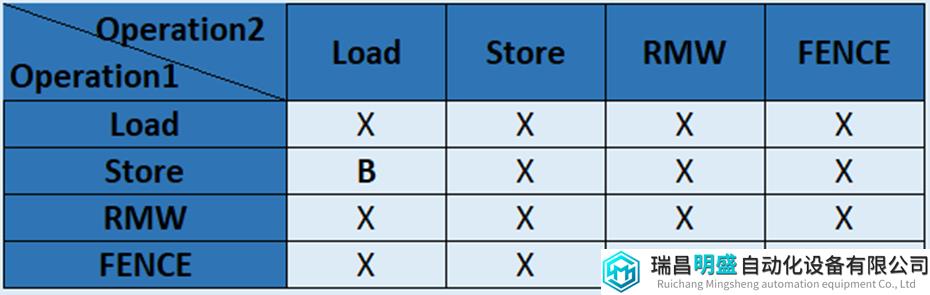
表7总结了TSO模型的排序规则,”X”表示强制排序,”B”表示如果操作指向同一个地址,则需要bypass数据。表中也包含了FENCE指令,SC模型不需要FENCE,因此在SC模型的排序规则表4中没有FENCE栏,SC模型的行为就好像在每个操作之前和之后都自带有FENCE效果。
表7 TSO模型的保序规则
为了理解TSO模型中atomic RMW的约束,可以把RMW理解成一笔store紧跟在一笔load之后,它们是不可拆分的。由于TSO模型的排序规则,RMW的load部分不能超过先前的load。乍一看,RMW的load部分可以bypass write buffer中更早的store指令,但这是不合法的。如果RMW的load部分bypass一个较早的store指令,因为RMW是一个原子对,那么RMW的store部分相当于也bypass了较早的store指令。但TSO中不允许store之间相互bypass,所以RMW的load部分也不能bypass之前的store指令。
6.4 TSO模型实现
TSO模型的实现类似于SC模型,只是为每个Core增加了一个FIFO类型的write buffer。关于这个实现,有几点要求:
Loads和stores按照每个Core的program order离开该Core。
Load要么bypass write buffer中的值,要么像以前一样等待选择器切换,从memory里去获得值。
Store进入FIFO write buffer的尾部,如果buffer已满,那么就暂停Core的执行。
当选择器选择Core Ci时,它执行下一次load或在write buffer头部的store操作。
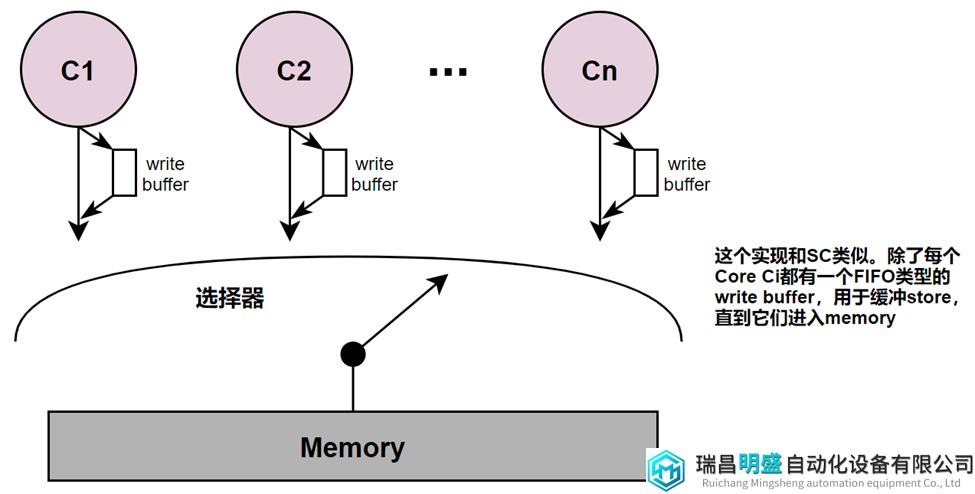
图11 简单的TSO模型实现
7、Relaxedmodel
Relaxed(weker) consistency model是相对SC和TSO模型来说的,任何比SC和TSO模型更宽松的模型都是Relaxed model。在前文中提过,SC模型为同一线程中load和store的所有四种组合(Load->Load, Load->Store, Store->Store, Store->Load)提供memory order保序。TSO组合为同一线程中load和store的三种组合(Load->Load, Load->Store, Store->Store)提供保序,不对 Store->Load做memory order保序,TSO模型中如果需要对 Store->Load做保序那么需要FENCE指令。
本节讲述的Relaxed model进一步弱化了保序条件,只寻求保留程序员需要的保序,从而允许软硬件更多的优化,促进性能提高。缺点是需要程序员推断哪些操作必须强制排序。
7.1 为何引入Relaxed模型
Relaxed模型优化了一些程序员不关心的指令排序,让这些指令可以乱序执行。以表8为例,大多数程序员期待r2总是会得到NEW值,因为执行流是:S1 -> S3 -> L1 load SET -> L2。类似的,大多数程序员期待r3也总会得到NEW值,因为执行流是:S2 -> S3 -> L1 load SET -> L3。
除了上述两个预期的执行流顺序外,SC和TSO模型还需要S1 -> S2和L2 -> L3的保序。不过这两个额外的顺序不影响程序正常运行,因此保留这些额外的顺序可能会限制实现优化以帮助提高性能。
表8 什么样的保序会使r2和r3都是NEW
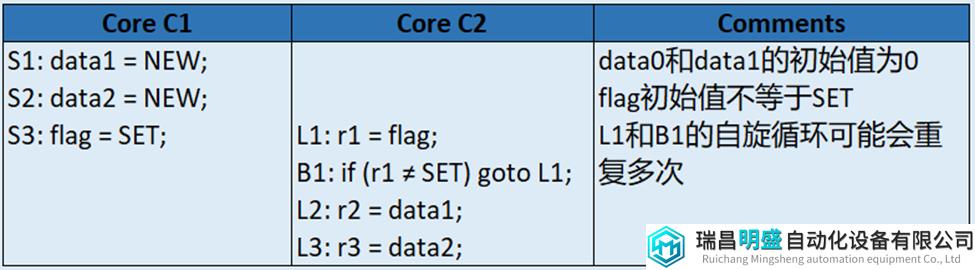
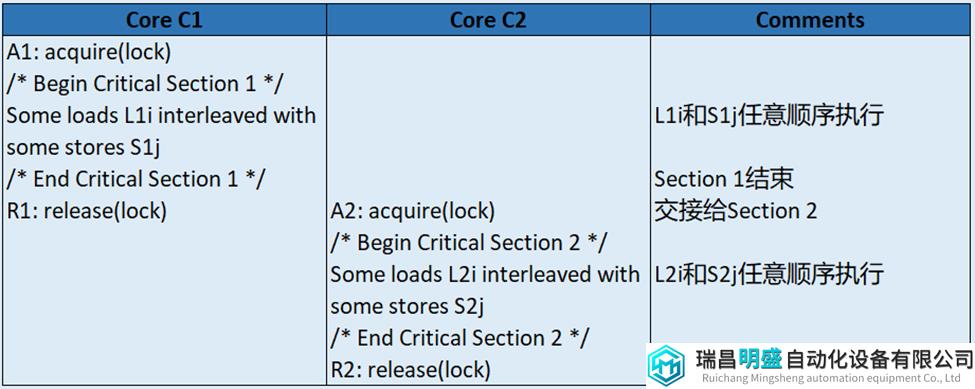
表9描述了使用同一lock(锁)在两个程序片段之间切换的一般情况。假设硬件支持lock acquire(例如,使用test-and-set对lock执行读-修改-写操作,并循环直到成功)和lock release(例如,store lock值为0)操作。Core C1通过acquire获得lock,让Section1中的Loads(L1i)和Stores(S1i)以任意顺序执行,然后release释放lock。类似的,Core C2在获得锁之后,让让Section2中的Loads(L2i)和Stores(S2i)以任意顺序执行。从Section1切换到Section2的正确操作取决于这些操作的顺序:
All L1i, All S1j -> R1 -> A2 -> All L2i, All S2j // (逗号“,”表示操作之间未指定顺序)
Core C1和C2程序的正常运行不依赖于每个Section内的loads和stores的任何排序,除非这些操作指向相同的地址(在这种情况下,需要操作排序以保持单线程的sequentiality),所以:
所有的L1i和S1j可以以任何顺序相对执行,并且所有的L2i和S2j可以以任何顺序相对执行。
如果正确的操作不依赖于许多loads和stores之间的顺序,那么通过放松它们之间的顺序可能会获得更高的性能,因为load和store通常比lock的acquire和release要频繁的多,所以这就是relaxed(weak)模型存在的意义。
表9 如何从section1切换到section2
7.2 Relaxed模型举例
因为Relaxed模型很多,为了方便说明,以XC(eXample relaxed Consistency model)模型来代表relaxed模型的基本思想和一些实现潜力。与SC和TSO一样,XC模型也假设存在global memory order。对不同地址的memory操作,XC模型允许它们乱序执行。但是对于相同地址的memory操作,XC和TSO的规则一致。
XC模型也提供了一个FENCE指令,以便程序员可以指示合适需要保序,这个FENCE指令的功能和TSO中的FENCE类似,除了有些体系结构中FENCE指令会指定不同的保序属性。FENCE指令不指定地址,同一个Core中两个FENCE指令也会保序。另外,FENCE指令不会影响其它Core的memory操作顺序。
表10位程序员应该如何在表8程序的基础上插入FENCE,以便程序可以在XC模型下正常运行。这些FENCE保证以下顺序:
S1, S2 -> F1 -> S3 -> L1 loads SET -> F2 -> L2, L3
F1 FENCE将S1,S2和S3隔开,确保S1和S2先于S3执行。F2 FENCE是为了防止在乱序指令中,L2,L3可能先于L1执行,这样的话,最终r2和r3的值可能为0,不符合程序的意图。
表10 为XC模型添加FENCE到表8的程序

图10为表10中XC模型的执行,其中Core C1的Store S1和S2乱序执行,Core C2的load L1和L2也乱序执行。但是,这两种乱序执行都不会影响程序的最终结果。因此,对程序员而言,这个XC模型执行等同于图11种描述的SC执行,其中两对操作没有乱序执行。
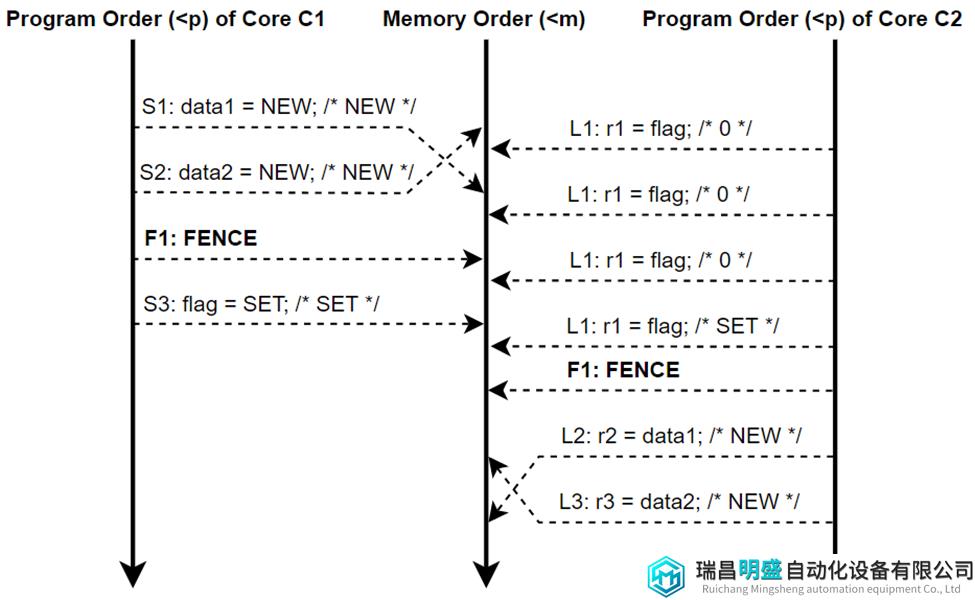
图12 表10的XC模型执行流
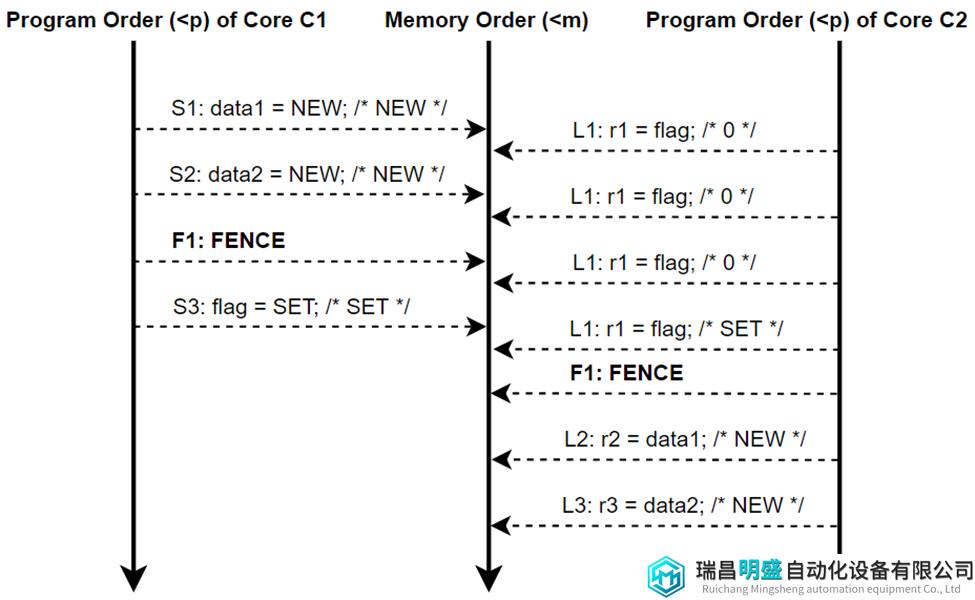
图13 表10的SC模型执行流
这个例子表明,有了足够的FENCE,XC模型对程序员来说就像SC模型一样。
7.3 Relaxed模型公式
这里使用与SC和TSO一样的公式表示符号来描述Relaxed(XC)模型公式。XC模型执行需要满足以下条件:
所有Cores按照以下顺序分别将它们的loads, stores和FENCE插入到memory order<m中:
如果L(a) <p FENCE,那么L(a)<m FENCE /* Load -> FENCE */
如果S(a) <p FENCE,那么S(a)<m FENCE /* Store -> FENCE */
如果FENCE<p FENCE,那么FENCE<m FENCE /* FENCE -> FENCE */
如果FENCE <p L(a),那么FENCE<m L(a) /* FENCE -> Load */
如果FENCE <p S(a),那么FENCE<m S(a) /* FENCE -> Store */
所有Cores按照以下顺序分别将它们同地址的的loads和stores插入到memory order<m中:
如果L(a) <p L’(a),那么L(a)<m L’(a) /* Load -> Load to same address */
如果L(a) <p S(a),那么L(a)<m S(a) /* Load -> Store to same address */
如果S(a) <p S’(a),那么S(a)<m S’ (a) /* Store -> Store to same address */
每次load都从它之前的最后一个相同地址的store中获取到它的值:
Value of L(a) = Value of MAX<m {S(a) | S(a) <m L(a) or <p L(a)} /* 和TSO类似*/
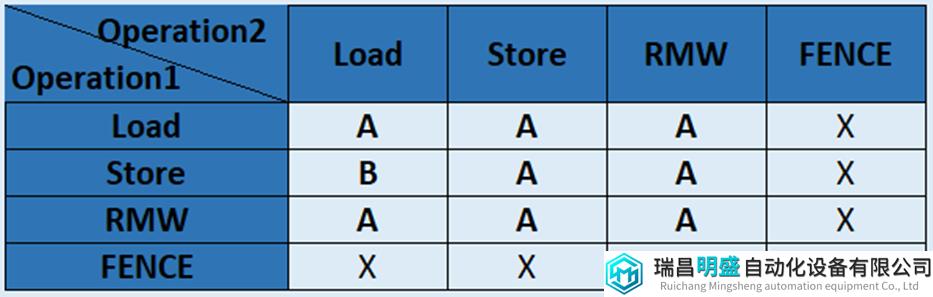
在表11中总结了这些保序规则,这个表与SC和TSO模型的保序表不大一样,”X”表示强制保序;”B”表示如果操作的地址相同的话,需要bypass数据;”A”表示只有当操作的地址相同时,才强制保序。
该表显示只有对相同地址的操作或使用了FENCE的情况下,XC模型才会强制保序。对于同地址的store->load与TSO模型规则一样,store可以在load之后进入global memory order,但load必须可以得到新store的值。
表11 XC模型保序规则
TSO模型中允许使用FIFO类型的write buffer,隐藏了部分或全部committed store的latency来提高性能。为了进一步提高性能,XC模型使用非FIFO类型的write buffer,允许多store数据的合并(merge),即program order上不连续的两个store可以写入到write buffer的同一个条目(entry)中。
在TSO模型中,RMW指令执行之前,需要Core排空FIFO类型的write buffer,获得读写权限,然后原子地执行RMW的load部分和store部分。在XC模型中,允许RMW的load部分和store部分与其它Stores乱序执行,因此Core执行RMW指令不需要排空write buffer。因此,只需要获得对访问地址的读写权限,然后执行原子地执行RMW的load部分和store部分就可以了。
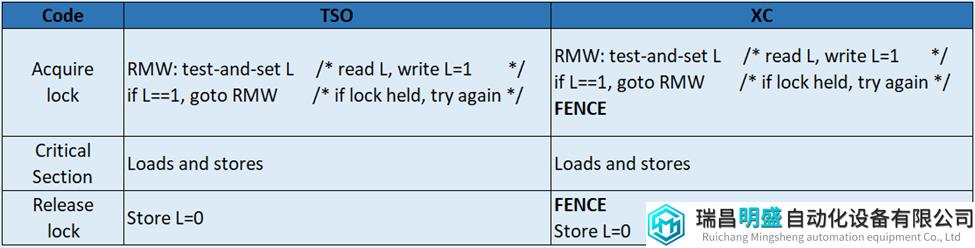
XC和TSO模型之间的一个重要区别是如何使用atomic RMW来实现同步。表12展示了一个代码片段,并带有TSO和XC模型的lock acquire与lock release。对于TSO模型,atomic RMW用于acquire lock,store用于release lock就足够了。但对于XC模型,情况更加复杂,atomic RMW无法限制其它操作的乱序执行,lock acquire后面必须跟一个FENCE。类似的,lock release也不受限制,也必须在lock release之前先执行FENCE。
表12 TSO和XC的同步对比
7.4 Relaxed模型实现
与实现SC和TSO模型的方法类似,图14为XC模型的实现。TSO模型实现中每个Core都通过FIFO write buffer与Shared memory分开。对于XC模型实现,每个Core将通过一个更通用的reorder unit(重排序单元)从Shared memory上分离出来,该单元可以对loads和stores进行重排序。关于这个实现,有几点要求:
每个Core Ci上的loads, stores和FENCE按照program order离开pipeline并进入Ci的reorder unit的尾部。
Core Ci的reorder unit会对操作进行排序,并按program order或下面指定的规则,将这些操作从它的尾部传递到头部。当FENCE指令到达reorder unit的头部时,它的使命就完成了。
当选择器选择Core Ci时,在Ci reorder unit头部的load或store会被执行。
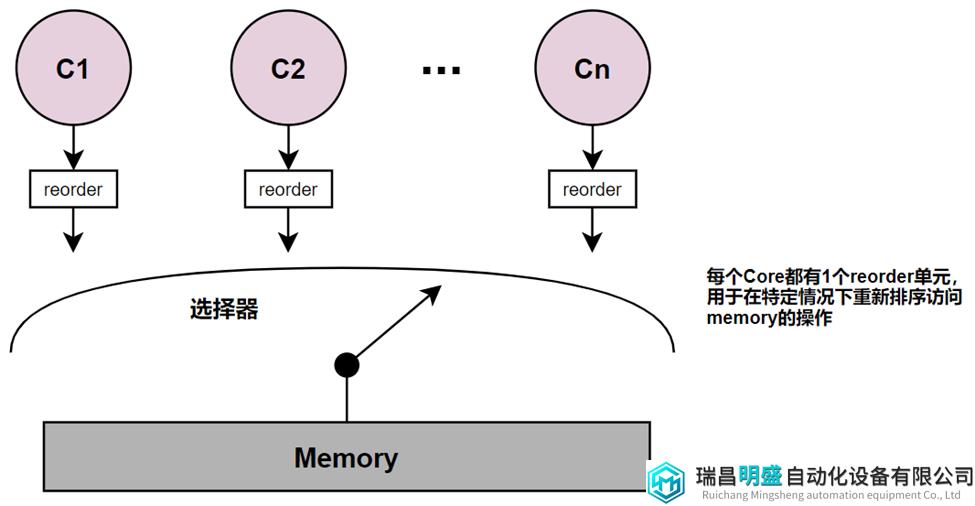
图14 简单的XC模型实现
对于(1) FENCE,(2) 同地址的操作,(3) bypass,reorder unit遵循以下规则:
FENCE可以用几种不同的方式实现,但它们必须强制执行保序,不管任何地址,reorder unit不能对它乱序处理:
Load -> FENCE, Store -> FENCE, FENCE -> FENCE, FENCE -> Load, FENCE -> Store
对同地址操作的,reorder unit也不能乱序处理:
Load -> Load, Load -> Store, Store -> Store (同地址)
Reorder unit必须确保后续的load可以得到同一个Core里前面store的数据。
7.5 Relaxed 模型的一些重要扩展
7.5.1 Release consistency
Release consistency(RC)的提出是基于一个观察:将所有同步操作用FENCE围在一起是多余的。随着对同步操作的深入理解,同步操作acquire只需要一个后面放一个FENCE,同步操作release只需要前面放一个FNECE。因此RC提供了ACQUIRE和RELEASE操作,它们和FENCE类似,但是只在一个方向上对memory进行保序,而不是像FENCE那样在两个方向上都进行保序。更一般地说,RC只需要:
ACQUIRE -> Load, Store (Load, Store -> ACQUIRE方向不保序)
Load, Store -> RELEASE (RELEASE -> Load, Store 方向不保序)
ACQUIRE -> ACQUIRE
ACQUIRE -> RELEASE
RELEASE -> ACQUIRE
RELEASE -> RELEASE
在RISC-V中,与RC类似,load和store指令可以携带其它语义:load指令可以携带ACQUIRE语义,store指令可以携带RELEASE语义,以及RMW指令可以携带ACQUIRE、RELEASE或两者都具有。有两种ACQUIRE语义:ACQUIRE-RCpc和ACQUIRE-RCsc。同样,也有两种RELEASE语义:RELEASE-RCpc和RELEASE-RCsc。Load(store)可以携带任何一种ACQUIRE(RELEASE)语义,而RMW只能携带RCsc语义。这些语义有如下保序:
ACQUIRE -> Load,Store (ACQUIRE代表ACQUIRE-RCSC和ACQUIRE-RCPC)
Load,Store -> RELEASE (RELEASE 代表RELEASE-RCSC和RELEASE-RCPC)
RELEASE-RCSC -> ACQUIRE-RCSC
7.5.2 Causality和Write atomicity
Causality(因果性):要求“如果我看到它并告诉你,那么你也会看到它”。以表13为例,其中Core C1执行store S1更新data1。当Core C2看到S1的结果(r1==NEW),执行FENCE F1,然后执行store S2更新data2。同样,当Core C3看到S2的结果(r2==NEW),执行FENCE F2,然后执行load L3观察store S1的值,如果Core C3保证能得到S1的值(r3==NEW),那么causality关系成立。否则,如果r3为0,则违反了causality关系。
表13 Causality: 如果我看到store并告诉你,你也必须看到

Write atomicity:它也称作store atomicity或multi-copy atomicity,要求一个core的store在逻辑上被所有其它cores同时看到。按照这个定义,XC模型是write atomicity,因为它的memory order(<m)指定了store在memory中生效的逻辑原子点。在此之前,没有其它core可以看到新store的值。在此之后,所有其它core必须看到新值或来自稍后store的值,但不能看到被store覆盖的之前值。Write atomicity允许一个core在其它core之前看到它自己store的值,这一点XC模型也要求。
8、Memory consistency model比较
图15画出了各个模型关系的Venn图。Relaxed模型分两个圆圈,第一个圆圈Power为Power内存模型,第二个圆圈MC2可以是Alpha, ARM, RMO或XC内存模型。
Power模型比TSO模型宽松(relaxed),TSO模型比SC模型宽松。
Alpha,ARM,RMO和XC模型(MC2)比TSO模型宽松,TSO模型比SC模型宽松。
对于MC2来说,目前与Power模型是无法互相比较的。
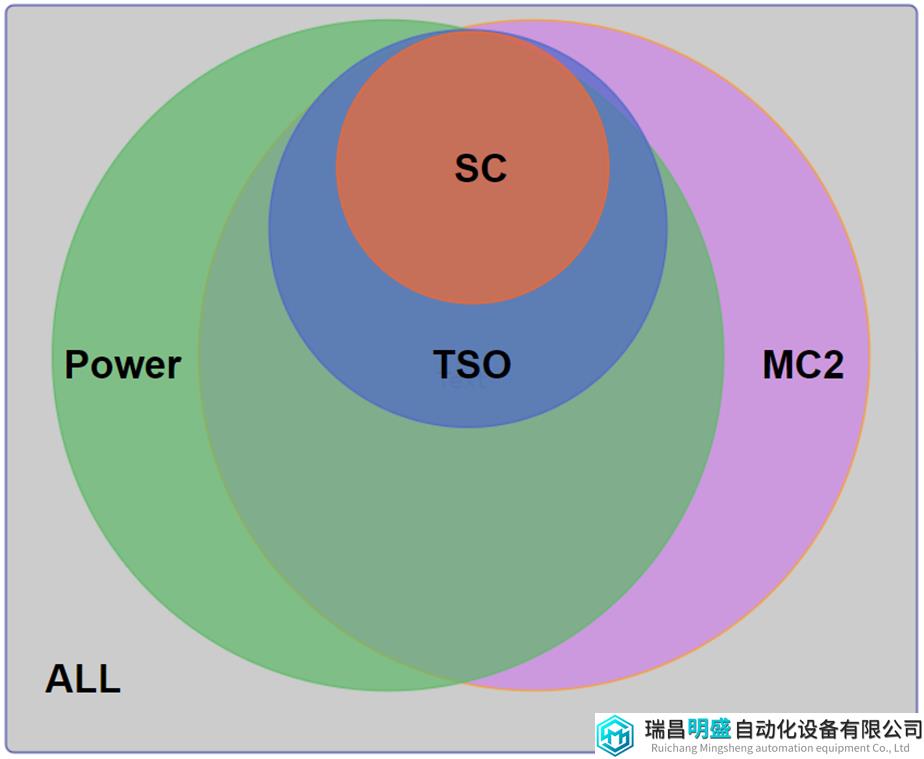
图15 memory模型对比Venn图
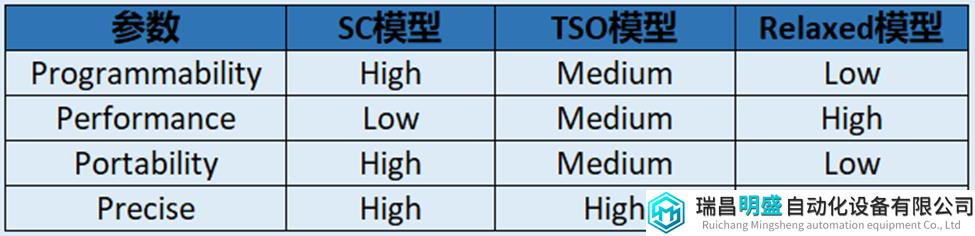
再结合4P原则比较下三种memory模型,可列出表14大致的比较结果。当然,这个表只是相对的比较,就比如Performance来说,Relaxed模型可以提供比TSO模型更好地性能,但对于许多Core微架构体系来说,这种差异更小。
表14 memory模型的4P比较
9、DRFfor SC
9.1 DRF for SC定义
DRF是Data Race Free的缩写,表示无数据竞争。当两个线程访问相同的memory地址,至少有一个访问是写操作,并且没有提供同步操作,那么就会发生Data Race(DR, 数据竞争)。通常来说(但不总是),DR是编程错误的结果,因此程序员需要编写DRF的代码。
DRF for SC编程需要软件程序员通过编写正确的同步程序和标记同步指令来确保程序在SC下是DRF。并要求硬件实现者将同步程序和标记同步指令映射到Relaxed模型所支持的FENCE和RMW操作,从而确保在Relaxed模型上执行的DRF程序总得效果是SC执行的。XC和大多数商业relaxed模型都有必须的FENCE和RMW指令来帮助达到DRF for SC,并且这种方法也是Java和C++高级语言(HLL) memory模型的基础。
表15和表16描述了在relaxed模型中DRF for SC的效果。两个表的共同点都是Core C1往两个不同的地址执行store操作(S1和S2),Core C2以相反的顺序load这两个位置的数据(L1和L2)。两个表的不同点在于,表15种的Core C2没有使用同步,表16的Core C2使用了lock同步机制。
由于表15的Core C2没有使用同步,所以L1和L2可以与Core C1的S1和S2并发乱序执行,因此最终(r1, r2)会有四种结果:(0, 0), (0, NEW), (NEW, 0), (NEW, NEW)。
表15 具有data race的XC执行 (有四种结果)
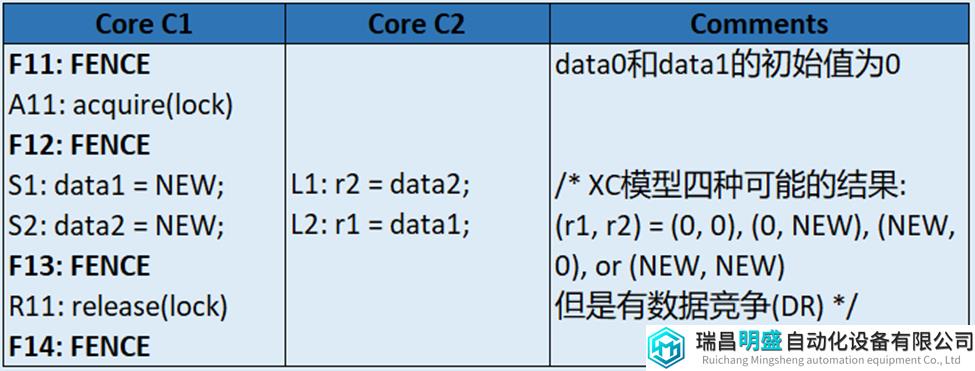
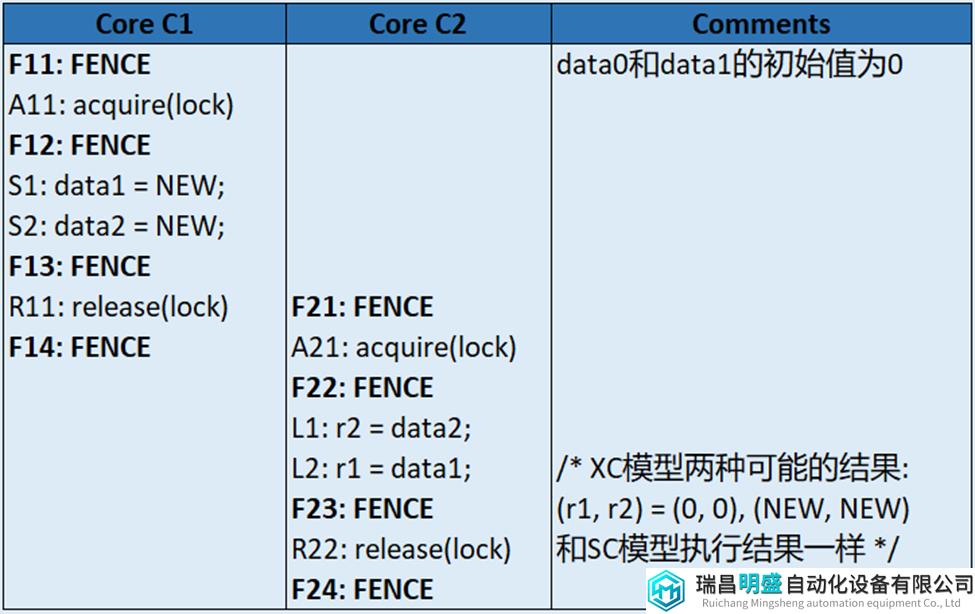
表16为Core C1和Core C2争抢相同的lock(同步机制)去执行各自操作。在这种情况下,先抢到lock的Core先执行,因此(r1, r2)会有两种结果:(0, 0), (NEW, NEW)。这种执行结果和SC下允许的结果一样。
表16 无data race的XC执行 (只有两种结果,像SC)
根据上述的例子,可以简单总结DRF for SC的定义:
首先XC模型会有一些memory操作是用于同步操作的,而其它memory操作是数据操作的。DRF是针对多线程(或多Cores)对同地址的数据操作而言,如果两笔数据操作发生race(竞争)且没有使用同步操作进行同步来避免,那么这个程序就不是DRF的。换句话说,一对相互冲突的数据操作(Di, Dj)当且仅当存在一对解决冲突的同步操作(Si, Sj),使得Di < m Si < mSj < m Dj时,Di < m Dj不存在数据竞争,也就是DRF for SC。
如果没有数据操作竞争,那么SC执行是DRF的。如果一个程序的所有SC执行都是DRF,那么这个程序就是DRF的。另外一个memory模型支持“SC for DRF programs”,那么所有DRF程序在这个memory模型上的执行都是SC执行的。这种支持通常需要memory模型提供一些特殊的同步操作。
支持“SC for DRF programs”允许程序员使用SC模型而不是更复杂的XC模型来推理他们写的程序,同时受益于XC模型的性能改进。总之,使用relaxed模型的程序员可以使用两种方式来推理他们的程序:
可以直接使用relaxed模型最本质的推理来判断模型会做什么和不会做什么;
可以插入足够的同步操作,以确保没有没有数据竞争(DRF),但同步操作竞争仍然是允许的,并使用相对简单的SC模型来推理他们的程序。
当然,推荐是使用后一种SC for DRF的方法,第一种方法通常是留给编写同步库或设备驱动程序等代码的专家使用的。
9.2 高级语言模型
前面讨论了硬件和底层软件之间接口的memory consistency models,讨论了软件期望什么,硬件实现者可以做什么。本节主要将高级语言(HLLs)的memory模型,确定:(a) HLL软件应该期望什么,(2) 编译器、运行系统和硬件实现者可能会做什么。图16展示了高级和底层语言的memory模型。
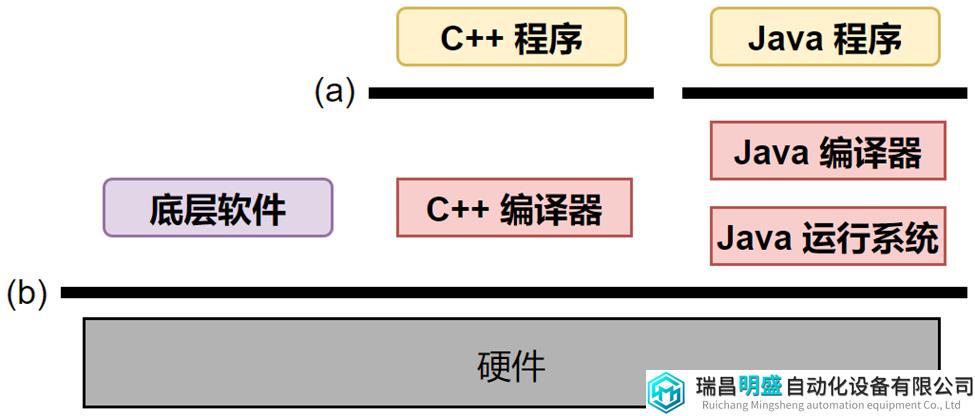
图16 (a) 高级语言,(b) 硬件memory模型
Java和C++两个高级语言的模型基础都是“SC for DRF”,允许synchronization同步竞争,但不允许数据竞争。程序员必须在变量可能竞争时将其标记为synchronization(使用注入atomic之类的关键字),或者使用Java的类似监控器的synchronized方法隐式创建同步锁。在所有情况下,只要没有数据竞争的程序都会遵守SC执行,因此,实现可以自由地乱序执行。
实现可以在同步访问之间乱序执行或减少内存访问。图17给出了一个例子。图17(a)为HLL代码,图17(b)为Core C1上的执行代码且没有分配寄存器(register allocation),图17(c)为Core C1上的执行代码且有分配寄存器给变量A,从而使load L2与load L1两个操作可以重排序并合并。因为使用“SC for DRF”规则判断,没有其它线程与变量A的load有数据冲突,所以这种合并是可行的。
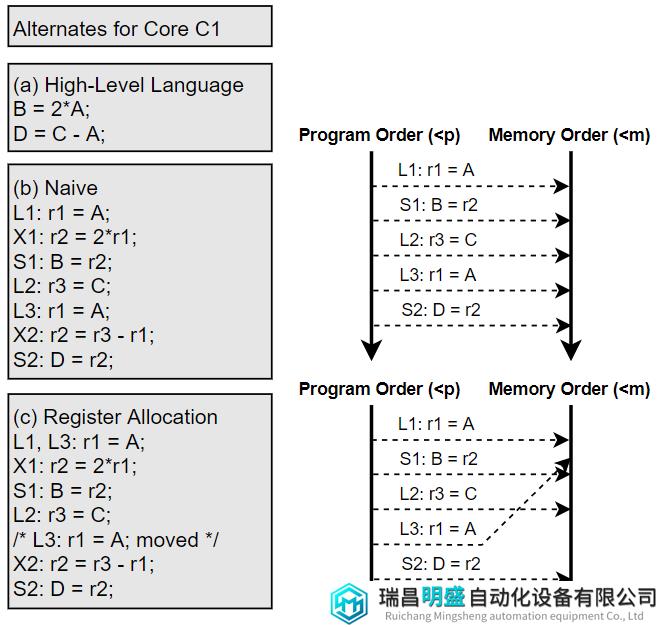
图17 寄存器分配影响memory order
除了寄存器分配,许多编译器和运行系统都可以对内存访问进行重排序,例如常量传播、公共表达式消除、循环裂变/融合、循环不变代码移动。软件流水线和指令调度等等。“SC for DRF”允许这些优化,编译器和运行系统可以生成与单线程性能相当的代码。因此,Java和SC提供了多种同步操作,编译器和运行系统只需要将HLL的同步操作转换为特定硬件的底层同步操作或FENCE,以提供必要的保序,其余情况下,可以重排序所有操作,来使性能最大化。
10、总结
为了解决多线程或多Core使用共享内存出现不确定的结果,业界定义了多种memory consistency model,消除软硬件在配合上的歧义。本文讲述了常见的SC、TSO和Relaxed模型,分析了创建该模型的原因、模型的使用例子、模型的公式和模型的实现,并总结了三种模型的优缺点。一个好的模型,应该在Programmability, Performance, Portability和Precision (4P原则)上都有较好的表现。最后介绍了“DRF for SC”的概念,它的出现主要是Relaxed模型分析起来过于复杂,需要一些同步机制来简化模型分析,并把更多的不确定结果转成确定结果,这一点在高级语言C++和Java都有应用。
本文没有对Relaxed模型里的其它模型做更深入描述,比如RISC-V的RVWMO和Arm的Other-multi-copy atomic,尽管它们两者很像。另外没有介绍relaxed模型中可能存在的address、data和control dependencies,这三者在有些模型里可以引起memory order,它们是语法上的依赖关系,而不是语义依赖关系,与寄存器的选取有关。
希望本文能帮助大家了解更多的memory consistency model知识。今天就写到这里了,后面的计划是分享下“软硬件虚拟化”的文章,但可能需要更长的时间。近期打算先把之前规划的分享视频做下,敬请期待。

微信号|chip_yes
微信公众号|专芯致志er
专注分享Arm architecture,AMBA,芯片验证,脚本,EDA工具,Linux等知识。