2024年英伟达GTC大会上,英伟达宣布了Drive Thor获得一系列客户采纳,包括比亚迪、小鹏和广汽埃安Hyper,不过没有极氪的名字,有点意外,极氪所在的吉利集团子公司芯擎则在3月20号的亿咖通Tech Day上布了与英伟达Orin对标的AD1000芯片,极氪很有可能不会使用Thor了。毫无意外,Drive Thor也采用了跟英伟达最新GPU B100/B200/GB200的Blackwell架构。
今天我们来着重看一下最新的Blackwell架构,大部分专业人士和投资者对新的Blackwell架构没有多少好感,发布新产品后,英伟达股价有所下跌,平心而论,Blackwell的确乏善可陈。
此外,英伟达也更改了对Thor算力的描述,https://nvidianews.nvidia.com/news/nvidia-drive-powers-next-generation-transportation,明确指出是1000TOPS,而在2022年9月的新闻稿里,https://nvidianews.nvidia.com/news/nvidia-unveils-drive-thor-centralized-car-computer-unifying-cluster-infotainment-automated-driving-and-parking-in-a-single-cost-saving-system明确指出是2000TOPS,当然这个没有点明模型精度,或许2000TOPS是FP4精度。Thor应该和Orin一样有多个版本,顶配算力1000TOPS,低配可能是500TOPS。
北京时间3月19日,采用英伟达新一代GPU架构Blackwell的首款产品B100和B200正式发布,同时发布的还有GB200系统以及售价可能超过500万美元的GB200 NVL72服务器。
简单地说就是将两颗H100放在了一起,就像苹果的M1系列一样。
苹果的M1Max可以持续扩展出多个产品,英伟达的B100也是如此,两者用的技术都一样,都是MCM。
英伟达三代GPU旗舰对比。
GB200的GPU部分,差不多等于拼凑了4个B100,性能是10000FLOPS@FP8,单个B100的性能是3500FLOPS@FP8。尽管有最新的高达1.8TB/s的NVLink加持,性能也只是勉强3倍。而通常车载网络是1GB/s,远低于NVLink,4个Orin级联顶多能算1.05倍也就是267TOPS的算力。
三款Blackwell架构产品的性能对比,B100可能是B200的降频版,会在2024年推出,而B200要等到2025年才能推出,和H100的单GPU die相比,B100和B200都是双GPU die,H100使用台积电N4工艺,800亿个晶体管,die size是814平方毫米,B100和B200都是使用台积电4NP工艺,die size可能是880平方毫米,晶体管密度提高,同时die size也大了,最终是1040亿晶体管。B100的性能是3500TFLOPS,H100 SXM5型是3958TFLOPS,性能没有提升,反而下降了,当然和性能稍差的H100 PCIe版相比大约提高了474TOFLOPS,但是H100 PCIe的TDP功耗只有300瓦,而B100是700瓦。和H100相比,B100提升不多,甚至没有提升。
2017年6月英伟达发表论文《MCM-GPU: Multi-Chip-Module GPUs for Continued Performance Scalability》提出了MCM设计,直到7年后才付诸产品。
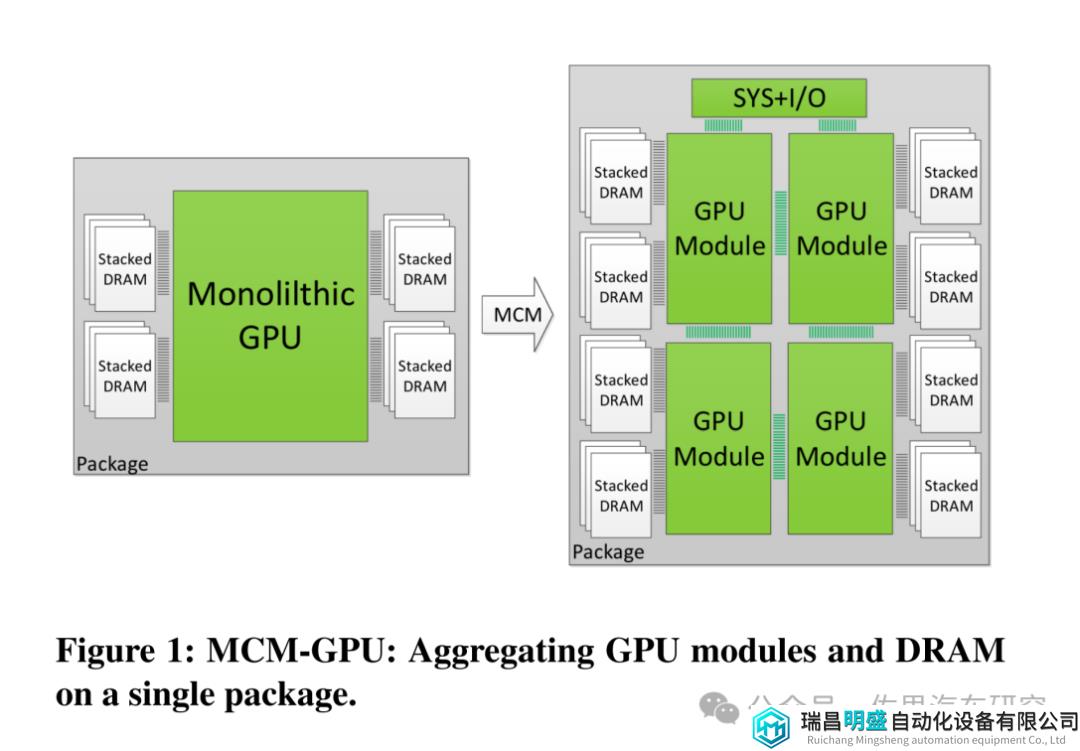
图片来源:NVIDIA
MCM-GPU设计基本就是现在比较火爆的Chiplet设计,但是英伟达一直未将MCM付诸实际设计中。英伟达一直坚持Monolithic单一光刻设计,这是因为die与die之间通讯带宽永远无法和monolithic内部的通讯带宽比,换句话说Chiplet不适合高AI算力场合,在纯CPU领域是Chiplet的最佳应用领域。
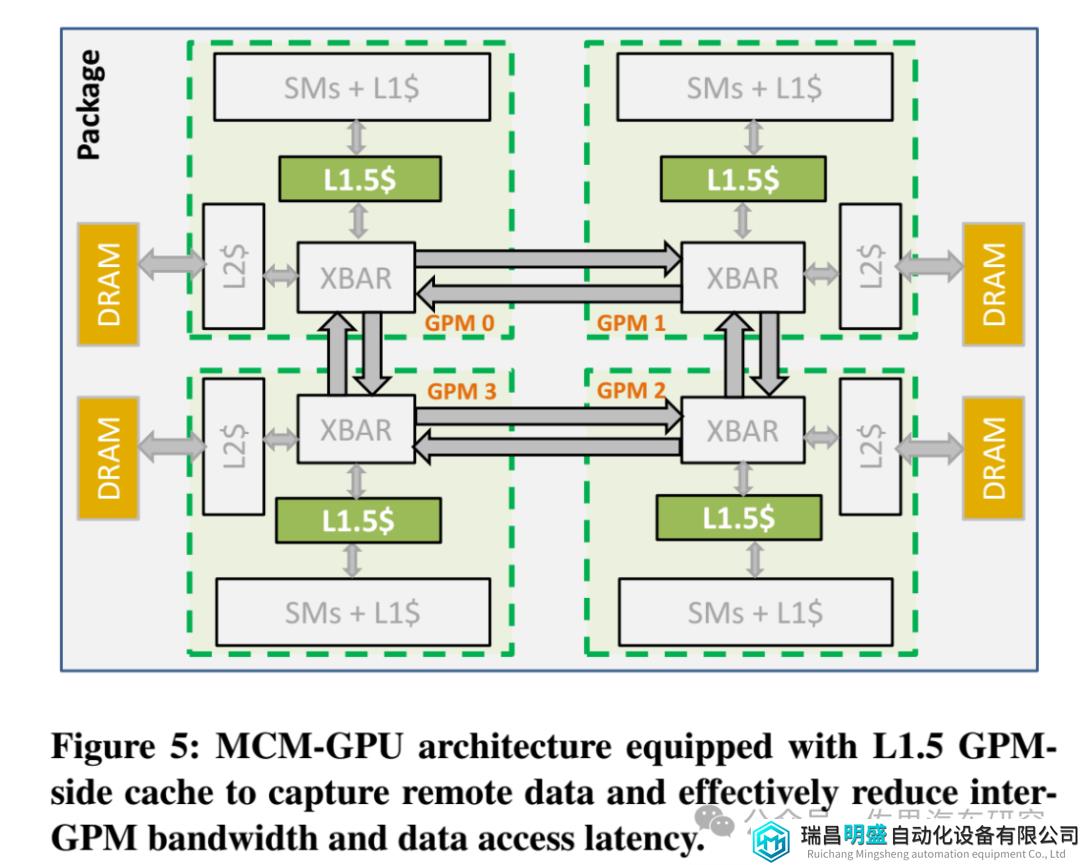
图片来源:NVIDIA
英伟达2017年论文提及的MCM-GPU架构如上图,英伟达在MCM-GPU架构里主要引入了L1.5缓存,它介于L1缓存和L2缓存之间,XBAR是Crossbar,英伟达的解释是XBAR负责将数据包从给定的源单元传输到特定的目标单元。有点像交换或路由。GPM就是GPU模块。
英伟达再次提到了芯片物理限制,因为光掩膜的限制,芯片的面积无法超过880(也有说是850)平方毫米,这是物理极限,除非光刻机领域出现革命性革新。同时芯片面积越大,良率就越低,成本就越高,这是Chiplet产生的根本原因,不过英伟达对Chiplet不屑一顾。英伟达一直坚持Monolithic单一光刻设计,这是因为Chiplet的die与die之间通讯带宽永远无法和monolithic内部的通讯带宽相提并论。
很多人引用这张图,芯片Die 尺寸750平方毫米的良率只有35.7%,50平方毫米是94.2%,实际没有这么夸张。英伟达的A100的die尺寸高达826平方毫米,H100的die尺寸也有814平方毫米,远超750平方毫米。但是英伟达依靠CUDA建立的护城河,产品具有极高溢价,不在乎成本高昂,英伟达有能力将成本转嫁到下游客户头上。
NVIDIA的H100利润率达到90%。同时也给出了估算的H100的成本构成,NVIDIA向台积电下订单,用 N4工艺制造 GPU 芯片,平均每颗成本 155 美元。NVIDIA从 SK 海力士(未来可能有三星、美光)采购六颗 HBM3芯片,成本大概 2000 美元。台积电生产出来的 GPU 和NVIDIA采购的 HBM3 芯片,一起送到台积电 CoWoS 封装产线,以性能折损最小的方式加工成 H100,成本大约 723 美元 。
B100的HBM是192GB的HBM3E,成本大概5000美元,die size加倍,制造和封装成本增加超过一倍,大概是2000美元,B100和B200的成本大约7000美元,英伟达一贯90%的利润率,B100售价大概7万美元,B200大概8万美元。
Thor的CPU部分可能会与英伟达Grace一样,使用ARM Neoverse的V2架构,核心数肯定不需要72颗,12或16核心足够了。Thor肯定无法使用昂贵的HBM,最多可能是GDDR6存储。顶配Thor的售价估计在1000美元左右,低配估计600美元,英伟达可能是考虑成本因素,才将算力缩水了一半。
英伟达是不是有些江郎才尽了?
免责说明:本文观点和数据仅供参考,和实际情况可能存在偏差。本文不构成投资建议,文中所有观点、数据仅代表笔者立场,不具有任何指导、投资和决策意见。