座舱SoC天花板是SA8295P?当然不是,AMD的一系列嵌入式处理器都可以碾压SA8295P,高通自己的座舱SoC如SA8255P也可以在AI领域超越SA8295P,主要原因是SA8295P是2021年初的产品,其设计范围在2020年就已确定了,却没想到座舱领域被中国车企卷得不成样子,遂在定位低于SA8295P的产品上也持续加大算力。
2023年9月19日,极越01首发高通骁龙8295智舱芯片。骁龙8295是最强的车机芯片,采用5nm制程工艺、8倍于8155的算力。在安兔兔车机性能榜单中,其跑分近70万,几乎是骁龙8155的2倍。就在同一天下午,高合在展翼日正式发布自研高算力智能座舱平台。该平台将首搭高通QCS8550芯片,实现行业首发,根据官方数据对比显示,全面优于SA8295。不出意外的话,比亚迪下一代也会用QCS8550。
两者最大性能差别就是AI算力。
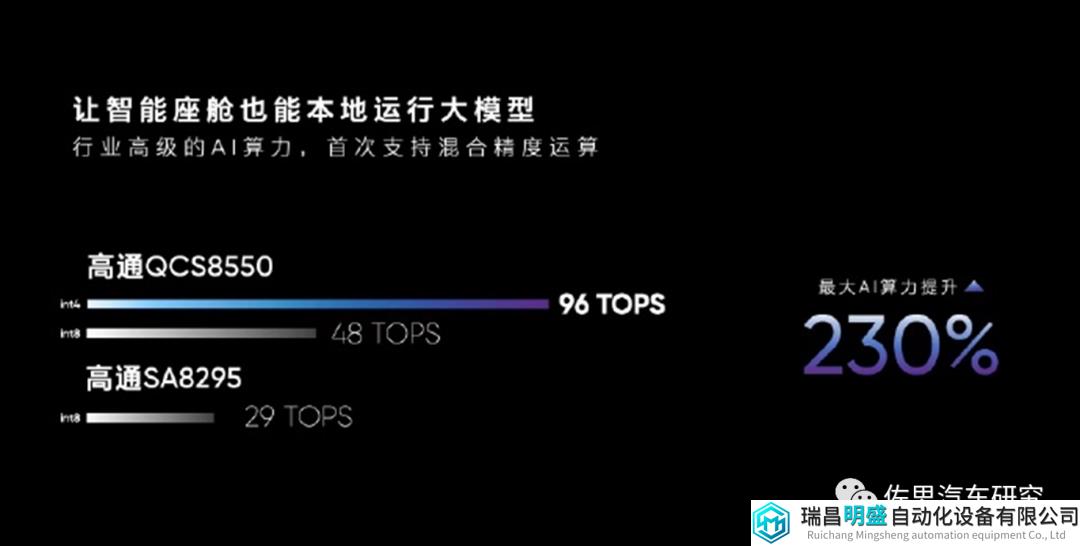
图片来源:高通
这张图有混淆视听之嫌,需要解释清楚,这个96TOPS是INT4精度下的算力,而SA8295P是不支持INT4精度的。不过即便比INT8精度,QCS8550也有48TOPS,也是遥遥领先。
CPU也碾压SA8295P,高达300kDMIPS,GPU是Adreno 740,算力达3.6TFLOPS,同样比SA8295P要高。就制造工艺而言,QCS8550是4纳米,SA8295P还是5纳米。
QCS8550是何方神圣?
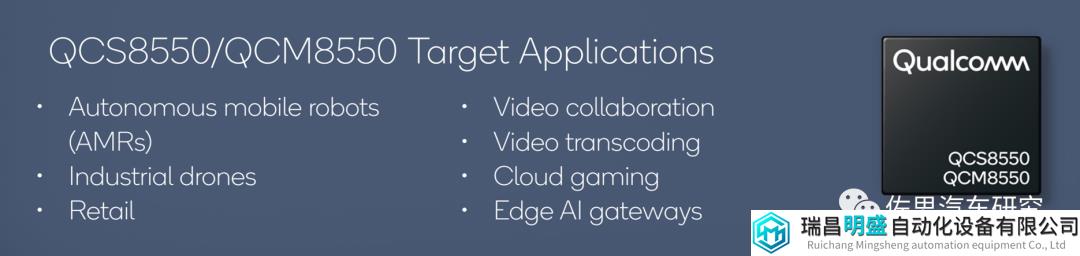
图片来源:高通
上图是高通对QCS8550/QCM8550的定位,显然它不是车规级芯片,不过这无所谓,特斯拉Model S那颗AMD显卡芯片连工业级都没做到,也没人指责过,这个至少是工业级,不是消费级的。而现在的Model 3/Y上用的AMD Ryzen V1000系列产品,是工业级产品,也不是车规级的,也没人敢指责特斯拉。再有就是国内顶级新能源大厂一直都是用高通非车规级模组做座舱,用非车规级做座舱的至少有30%以上。
高通QCS8550/QCM8550的参数

图片来源:高通
QCM就是带modem。看一眼这个CPU配置,略有经验的人便能看出,这就是手机领域骁龙8gen2的修改版,实际单看型号也能看出,8Gen2的型号就是SM8550。
骁龙8Gen3和8Gen2对比
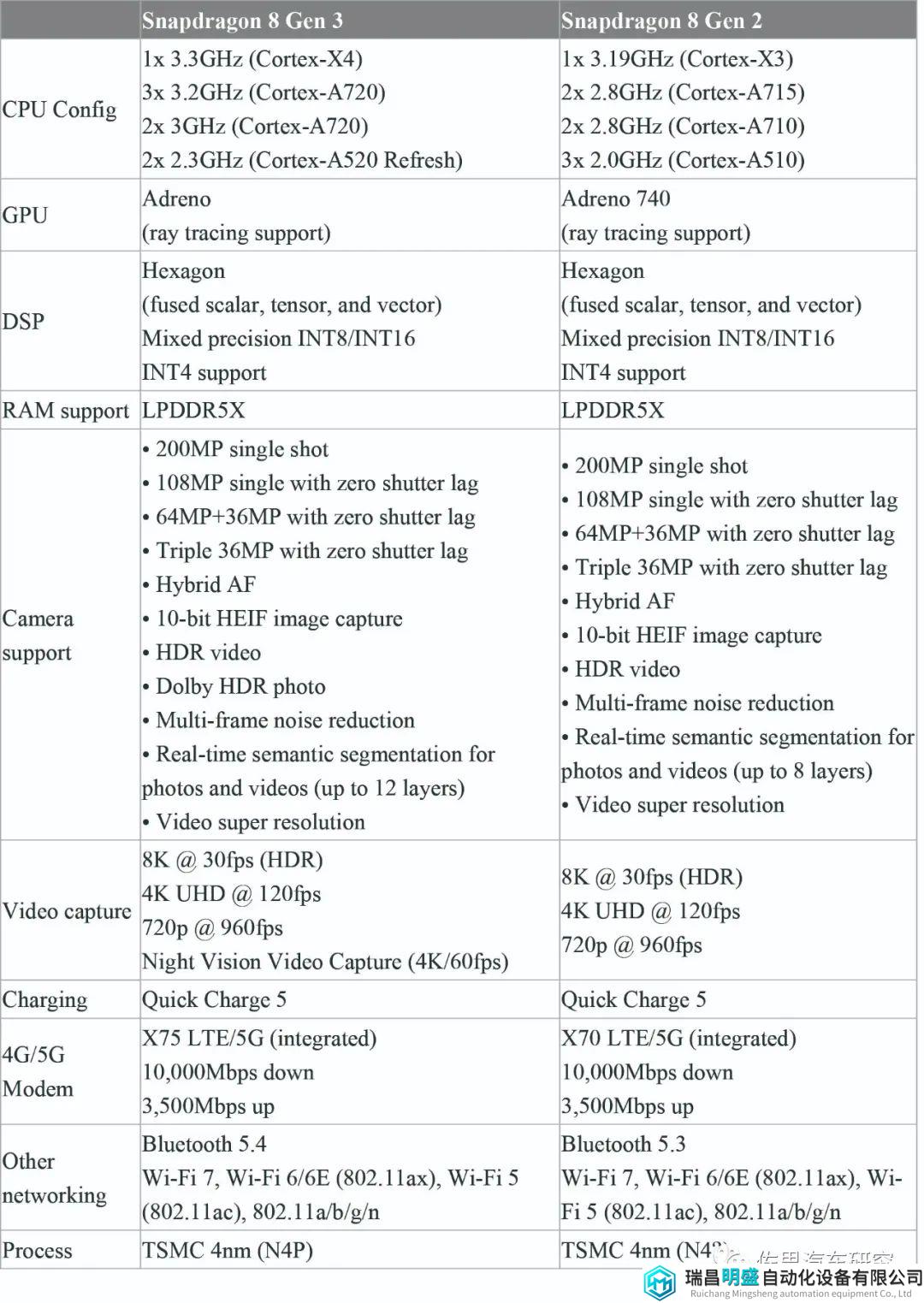
https://www.androidauthority.com/snapdragon-8-gen-3-vs-snapdragon-8-gen-2-3381660/
上表对比后不难发现,QCS8550就是8Gen2,两者完全一致。
强大的AI算力不难做到,难以做到的是低成本下的高AI算力,而高通最擅长的就是低成本下的AI算力。对芯片来说硬件成本基本等同于die size面积大小,高通SoC 的die size一般都很小,一般都低于120平方毫米,而英伟达Orin和华为MDC 610要400平方毫米以上。座舱SoC中,高通的AI算力异乎寻常地强,这个48TOPS真能运行大模型么?当然不能运行ChatGPT3这种大模型,就算单张H100也不能,流畅运行ChatGPT3至少需要8张H100和两片6千美元的CPU芯片。
高通的AI算力这么强主要源自其独特的DSP架构和VLIW指令集,其渊源是ATI,早在2004年高通与ATI达成合作计划,决定把ATI公司的3D图形技术集成到高通下一代移动处理器之中,看中的就是ATI Imageon。后来ATI被AMD收购,ATI Imageon也更名为AMD Imageon。2009年,高通以6500万美元收购了AMD的移动设备资产,取得了AMD的矢量绘图与3D绘图技术相关知识产权,不用再向AMD缴纳技术授权费用。后来高通独立发展出了一种全新的GPU品牌体系——Adreno。Adreno GPU此后不断开花结果,历经多年演化,占据了移动GPU市场的主导地位。
实际ATI的技术不止供养了日后的Adreno,ATI也开发了VLIW技术。以ATI Radeon HD 5800为例,GPU由20个SIMD计算引擎组成,每个SIMD计算引擎由16个线程处理器单元(Thread Processor – TP)组成。而每个TP则是一个5-way的VLIW Processor。虽然后来VLIW退出GPU领域,但在DSP领域大放异彩,在AI时代更是大展神威,助力高通成为移动霸主。
VLIW就是超长指令集。
几种指令集的对比
VLIW类似于多条RISC指令的集合,VLIW的思路是硬件尽量简单化,硬件只负责取指令和执行指令,其余一概不管,把困难推给编译器,让编译器来做指令调度。首先我们还得知道编译器是什么,比如C语言、C++、Java这样的程序,当我们一行一行写下代码后,需要经过编译器的“翻译”才能变成可执行程序才可以执行,才可以实现代码到程序的转变。电脑(其实主要就是CPU)只认识0或1这两个数字。所有写的一切代码,都需要编译器帮我们编译也就是翻译成大量的01代码(实际中间还有一步就是生成汇编代码),才是CPU的“母语”,CPU才会熟练的帮我们飞速般去执行。
VLIW把多条独立的指令打包为一个指令集并交给编译器,编译器根据指令的不同形式判断指令的运行周期,将运行周期比较一致的指令安排在一起发射并执行。VLIW最大好处是实现了并行计算,比如VLIW的数据总线长如果是1024比特,那么对4比特数据,一次可以取256个,取到数据进行并行计算(前提是你得有256套ALU加寄存器之类的硬件系统),一个指令就可以完成256个周期运算,如同256个内核。缺点很明显,如果这256个计算中有一个卡壳了,那么其余255个必须停下来等待这个计算完成,这就是锁步,大家的步伐必须完全一致,而传统的超标量CPU不会,它可以乱序执行。还有一个缺点就是即使只有10个指令,其余那246个也必须空转,这意味着功耗很高。这与近期的SIMD可变矢量长度非常近似,但SIMD只是一次性取了256个4比特数据,VLIW完全依靠软件就实现了并行计算。1994年英特尔和惠普签订协议,宣布共同开发面向高性能计算(HPC)的处理器,也就是后来的Itanium,安腾。他们以VLIW指令作为基础,提出了显式并行指令集运算EPIC( Explicitly parallel instruction computing)。不过这对开放式软件系统挑战太大,2000年以后就消失了,但VLIW+DSP慢慢崛起了。
VLIW处理器示意图
DSP与传统CPU或GPU最大不同是其采用哈佛架构,将存储器空间划分成两个,分别存储程序和数据。它们有两组总线连接到处理器核,允许同时对它们进行访问,每个存储器独立编址,独立访问。这种安排将处理器的数据吞吐率加倍,更重要的是同时为处理器核提供数据与指令。DSP芯片广泛采用2-6级流水线以减少指令执行时间,从而增强了处理器的处理能力。这可使指令执行能完全重叠,每个指令周期内,不同的指令都处于激活状态。更像是脉动处理器,数据一次导入,流转周期很长,效率极高。DSP最强之处还有它可实现零开销循环,而AI引擎通常就是零开销循环结构,不会发生任何用于比较和分支的分支控制开销。
但DSP本质还是近似CPU的设计,不适合做并行计算,它最适合的是图像压缩算法或快速傅里叶变换(FFT)这种算法,即串行数据流形式的计算,而VLIW是天生并行指令集,二者结合后就非常适合AI运算,AI运算即是并行矩阵运算,也是数据流形式。
高通的AI表现与编译器关系非常密切,但大家都知道编译器是静态的,无法实现动态调整,因此某些模型可能在高通芯片表现很差,很多搞座舱的都没使用过高通的DSP运算能力,智能驾驶领域用DSP的人也很少,因为太难用了。而高通唯一一款通用AI计算器AI100上,高通没有使用其最擅长的DSP架构,而是传统的MAC阵列架构,主要也是为了尽可能扩大应用面。
大模型是可以跑,但谁都不会公布延迟是多少毫秒,AI算力这游戏还是蛮有趣的。